



Reading Images, Drawing Dreams: VLMs meet Diffusion Models
Lesson 5: Ava learns to see

Ava’s leveling up - week after week.
Remember when we kicked this off? Just three weeks ago, she was basically a clueless little graph, processing messages with zero memory. You’d tell her your name, and next time? Poof - gone. She’d ask again like you’d never met.
Two weeks ago, things changed. We gave her memory - short-term (with summaries) and long-term. Suddenly, she could store and retrieve memories using embeddings in Qdrant. Now, she could remember things from yesterday… or even a month ago.
Last week? We gave her a voice. With STT (Whisper) and TTS (ElevenLabs), Ava could listen and talk back, making conversations feel way more real.
And today?
Today, my friend, Ava opens her eyes. Today, she learns to see 👀

This is the fifth lesson of “Ava: The Whatsapp Agent” course. This lesson builds on the theory and code covered in the previous ones, so be sure to check them out if you haven’t already!
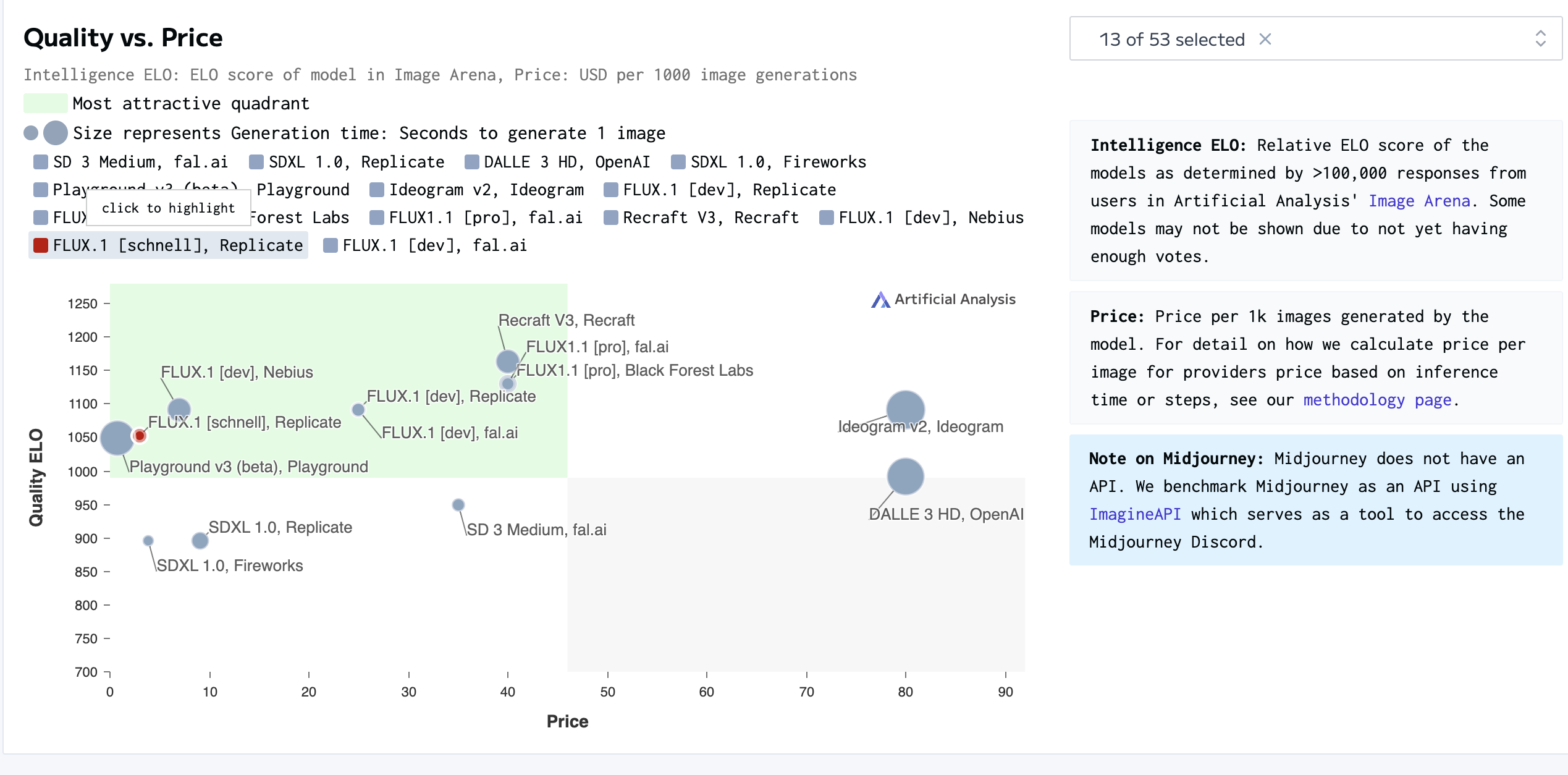
Ava’s Vision Pipeline

Ava’s vision pipeline works a lot like the audio pipeline.
Instead of converting speech to text and back, we’re dealing with images: processing what comes in and generating fresh ones to send back.
Take a look at the diagram above to see what I mean.
It all starts when I send a picture of my latest hobby (golf). And yes, before you say anything - I know my posture is awful 😅
The image gets processed (we’ll dive into the details later), and a description is sent into the LangGraph workflow. That description, along with my message, helps generate a response - sometimes with an accompanying image. We’ll explore how scenarios are shaped using the incoming message, chat history, memories, and even current activities.
So, in a nutshell, there are two main flows: one for handling images coming in and another for generating and sending new ones out.
Image In: Visual Language Models (VLM)

Vision Language Models (VLMs) process both images and text, generating text-based insights from visual input. They help with tasks like object recognition, image captioning, and answering questions about images. Some even understand spatial relationships, identifying objects or their positions.
For Ava, VLMs are key to making sense of incoming images. They let her analyze pictures, describe them accurately, and generate responses that go beyond just text - bringing real context and understanding into conversations.
We chose Llama 3.2 90B for our use case. No surprise, we’re running it on Groq, as always. You can check out the full list of Groq models here!
To integrate the VLM into Ava’s codebase, we built the ImageToText class as part of Ava’s modules. Take a look at the class below!

The way this class works is pretty straightforward - just check out the analyze_image method. It grabs the image, sends it to the Groq model, and requests a detailed description.
Going back to the “golf” example, my detailed description would be:
A guy in white totally struggling at golf.Ava can be ruthless…
Image Out: Diffusion Models

Diffusion models are a type of generative AI that create images by refining random noise step by step until a clear picture emerges. They learn from training data to produce diverse, high-quality images without copying exact examples.
For Ava, diffusion models are crucial for generating realistic and context-aware images. Whether she’s responding with a visual or illustrating a concept, these models ensure her image outputs match the conversation while staying creative and unique.
There are tons of diffusion models out there - growing fast! - but we found that FLUX.1 gave us solid results, creating the realistic images we wanted for Ava’s simulated life.
Plus, it’s free to use on the Together.ai platform, which is a huge bonus! 😁

Just like we did with image descriptions, we’ve built a complementary TextToImage class under Ava’s modules.
The workflow is simple: first, we generate a scenario based on the chat history and Ava’s activities - check out the create_scenario method below!

Next, we use this scenario to craft a prompt for image generation, adding guardrails, context, and other relevant details.
The generate_image method then saves the output image to the filesystem and stores its path in the LangGraph state.
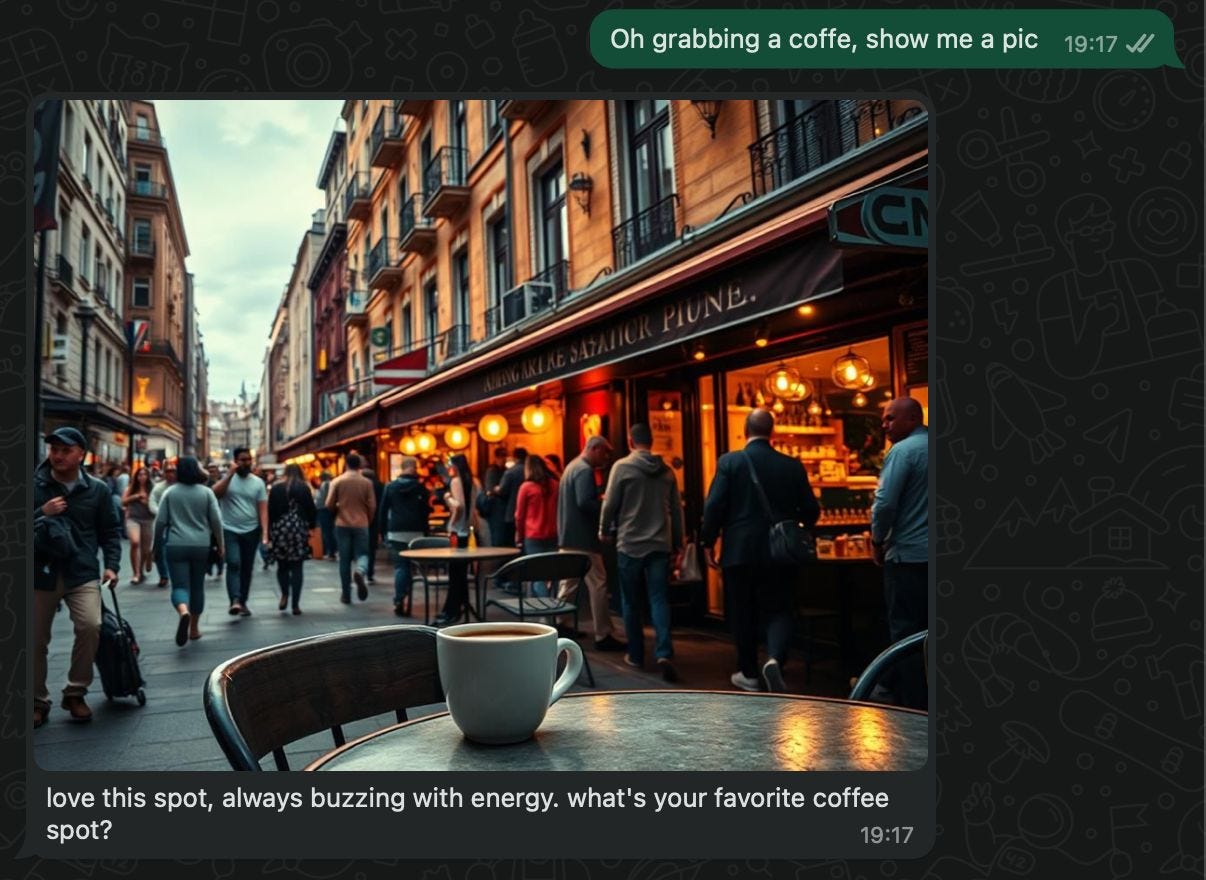
Finally, the image gets sent back to the user via the WhatsApp endpoint hook, giving them a visual representation of what Ava is seeing!
Check out the example below - Ava is relaxing with a coffee in what looks like a local market ☕
And that’s all for today! 🙌
Just a quick reminder - Lesson 6 will be available next Wednesday, March 12th. Plus, don’t forget there’s a complementary video lesson on Jesús Copado’s YouTube channel.
We strongly recommend checking out both resources (written lessons and video lessons) to maximize your learning experience! 🙂
Great article man, given the complexities and different parts going underneath VLMs and Diffusion Models, you guys managed to summarize it pretty well! 10/10 🔥