

When Llama meets Rick Sanchez
Learning LLM finetuning by building your own Rick-speaking AI assistant

Maybe it’s obvious from the title (and also the picture below), but yeah, I’m a huge Rick and Morty fan. So, the other day I was looking for a project where I could play around with finetuning LLMs and then it hit me: what if I finetuned an LLM to talk like Rick Sanchez? 🤔
But wait, why stop there? What if I made a repo so anyone could try it out?
Actually … what if I shared the whole thing right here, in my newsletter?
Well, here it is. Ladies and gentlemen, let me introduce you to my latest project:
Rick LLM!! 🛸

If you want your own “local” Rick, go ahead and clone this repo!
Project Design

This project can be divided into three main components:
💠 Dataset creation - Creating a custom dataset from Rick and Morty transcripts in ShareGPT format.
💠 Model finetuning - Finetuning Llama 3.1 8B using Unsloth on Lambda Labs GPUs.
💠 Model deployment - Converting and deploying the model to Ollama for local use.
Let’s explore each one in detail.
Dataset Creation
To train the LLM, we need an instruct dataset. This dataset will contain the instructions for the model to follow. In this case, we want Llama 3.1 to speak like Rick Sanchez, so we’ll create a dataset with Rick and Morty transcripts in ShareGPT format.
This dataset will be pushed to Hugging Face, so we can use it later in the finetuning process.
You have all the dataset related code here
I’ve already pushed the dataset to The Neural Maze Hugging Face organisation, so feel free to check it out there.
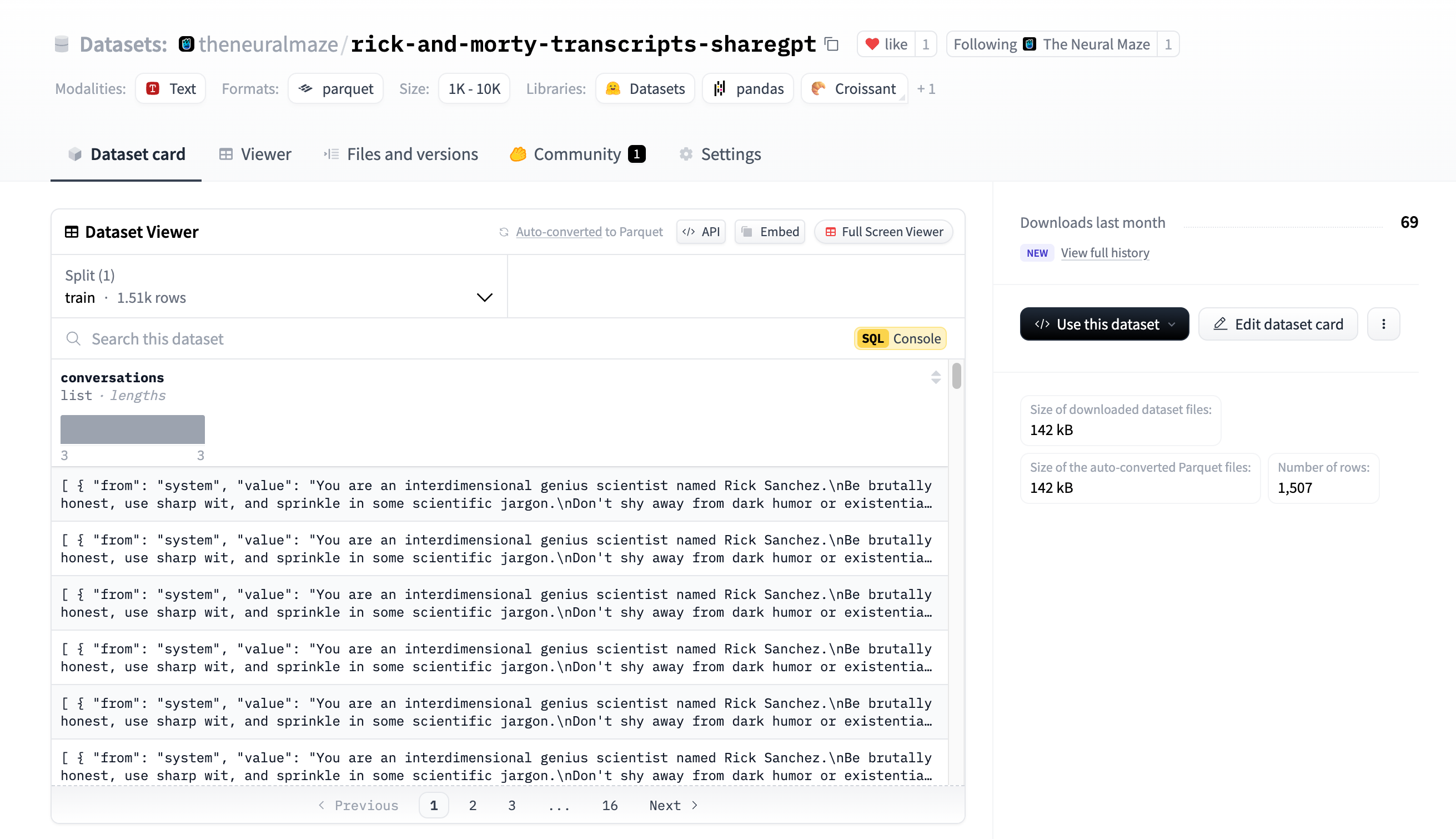
Each row has the following format - remember we are following ShareGPT style:
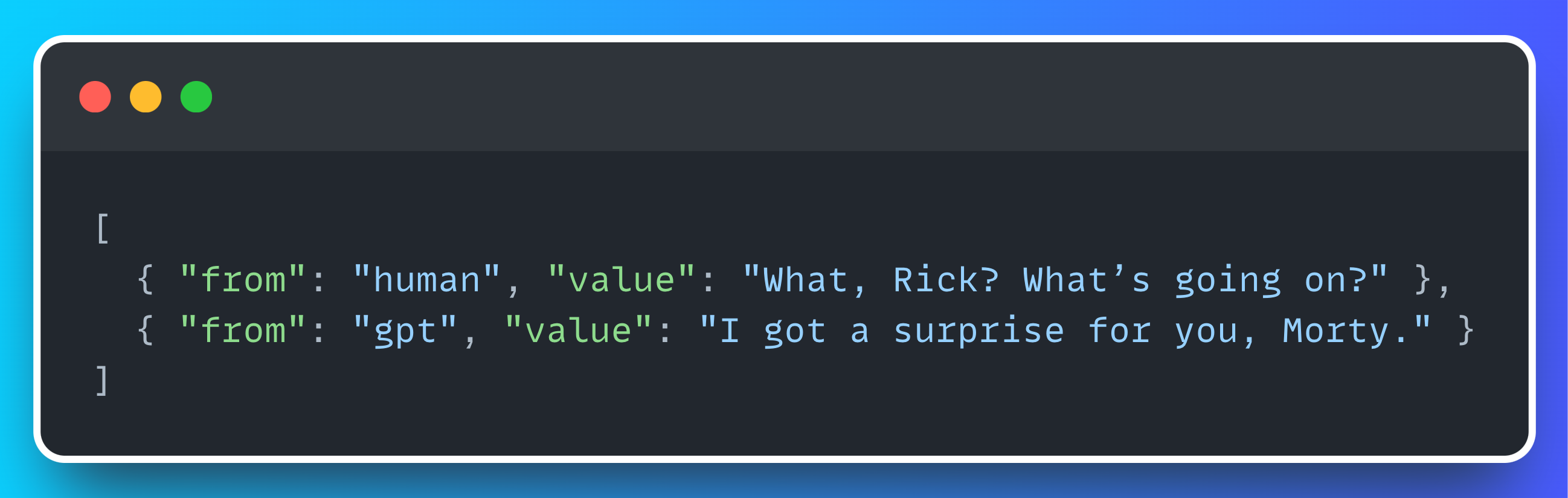
If you’re a nerd like me, you’ll recognise these as two of the first lines of Episode 1
Model finetuning with Unsloth
Now that we have the dataset, it’s time for the fun part: finetuning Llama 3.1 8B!
We’ll be using the Unsloth library for this, as it offers a lot of optimizations that make the process faster, more efficient, and much cheaper! 💸
Instead of a full finetune, we are going to apply a LoRA finetuning. LoRA is a technique that allows us to finetune the model without retraining all the weights. This is a great way to save time and resources, although not as accurate as a full finetuning.

If you want to learn more about the different types of finetuning, I highly recommend checking out Maxime Labonne’s posts!
First, we'll load the dataset along with the model and tokenizer.
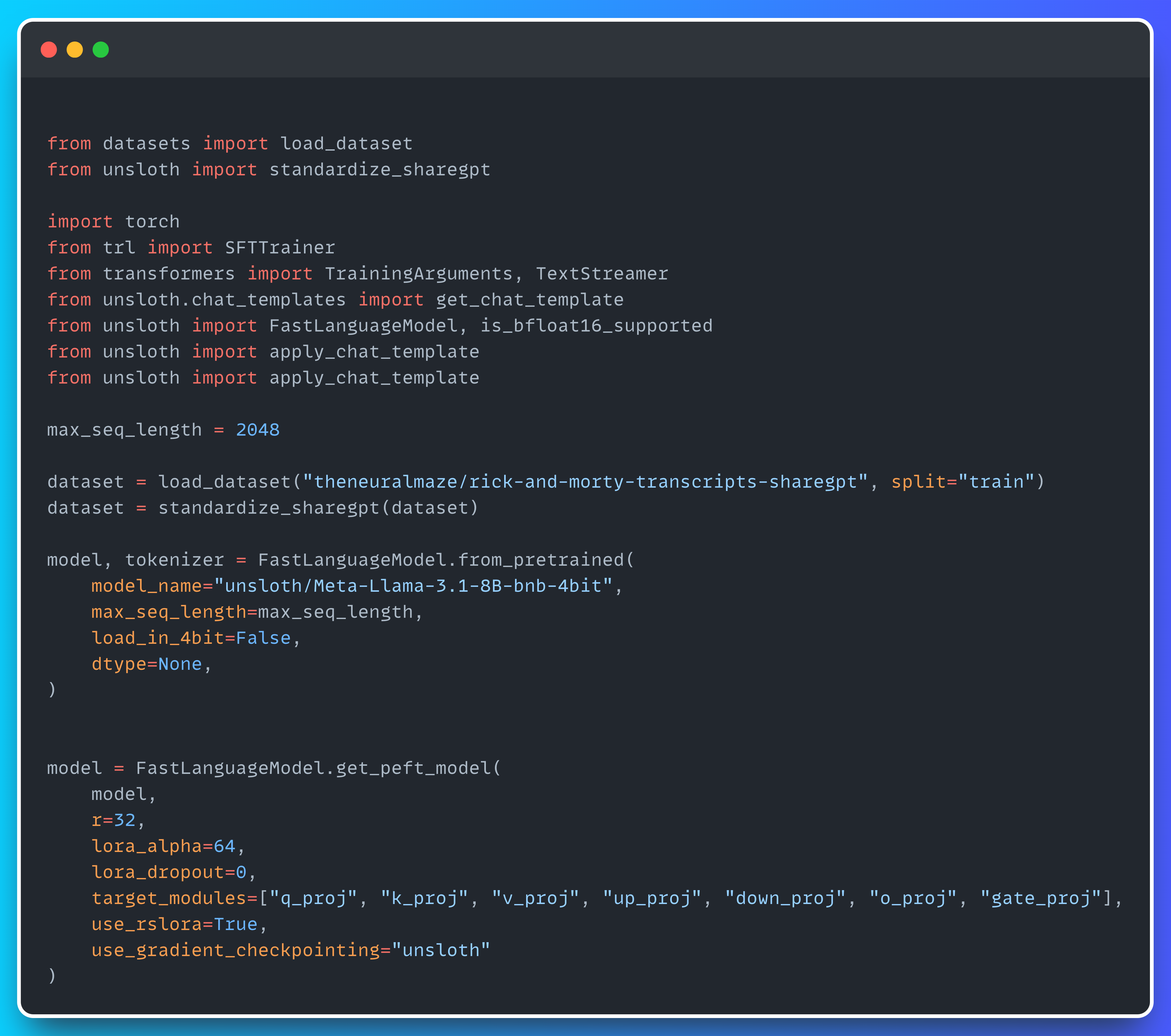
After that, we need to apply the chat template to the dataset. In my case, I chose the ChatML template.

Finally, just create the SFTTrainer and … train!

If you are feeling overwhelmed but the huge number of parameters, don’t worry, I felt the same way! For a comprehensive explanation of each one, I recommend checking out Unsloth’s LoRA Parameters Encyclopedia.
No GPU available? Welcome to Lambda
If you’ve tried running the previous code snippets and you are GPU poor, like me, you might be wondering: “What did I do wrong?” 😩
The answer is: nothing! You just need a GPU, my friend. That’s why I’ve opted for a GPU cloud provider - specifically, Lambda Labs.

I’m not going to get into the details of configuring the cloud, as you can easily follow the README, but if you’ve set everything correctly, you should be ready to start finetuning your Rick LLM - it’s basically running the Unsloth code from the previous section on a remote instance, simple as that 🤣

The finetune job will generate two files, which will be pushed to Hugging Face: a GGUF file and the Modelfile.
The GGUF file contains a quantised version of the finetuned LLama 3.1 weights, while the Modelfile is just a blueprint for Ollama models. More on Ollama in the next (and last) section 👇
Exporting to Ollama
Now that we have the GGUF and the Modelfile in HuggingFace, we need to download them to our local machine. Once the two files are in our computer, we can use the Ollama CLI to create the model.
ollama create rick-llm -f ModelfileOnce the model is created, you can finally start chatting with Rick Sanchez! 🎉🎉🎉
ollama run rick-llm
And that’s all for today friends! I’ll see you again next Wednesday but, until then:
Wubba Lubba Dub Dub!
(Sorry for that 🙏)
![100+] Fondos de fotos de Rick Sanchez | Wallpapers.com](https://substackcdn.com/image/fetch/$s_!rwwa!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc40cd43b-5784-47a3-8332-fcf0c362fd50_1920x1080.jpeg "100+] Fondos de fotos de Rick Sanchez | Wallpapers.com")