

The RL Algorithm Behind DeepSeek's Reasoning Models
Finetuning Sessions · Lesson 6 / 8


If you followed our last guide and tried setting up a reinforcement learning pipeline with PPO, you probably hit a wall fast … 👇

You spin up your policy model, your reference model, your reward model, and your value model… and watch your GPUs tap out before training even starts 😄
PPO delivers strong results, but it's computationally punishing.
The value model (the "critic") is typically a neural network roughly the same size as the policy model itself, which effectively doubles your memory footprint and drags down training speed.
For most teams, this turns post-training into more of an infrastructure problem than a research one.
To push the limits of LLM reasoning without breaking the bank, the industry needed a leaner, meaner optimizer.
Enter Group Relative Policy Optimization (GRPO). Pioneered by DeepSeek, GRPO asks a radical question: what if we didn't need a critic model at all? 😮
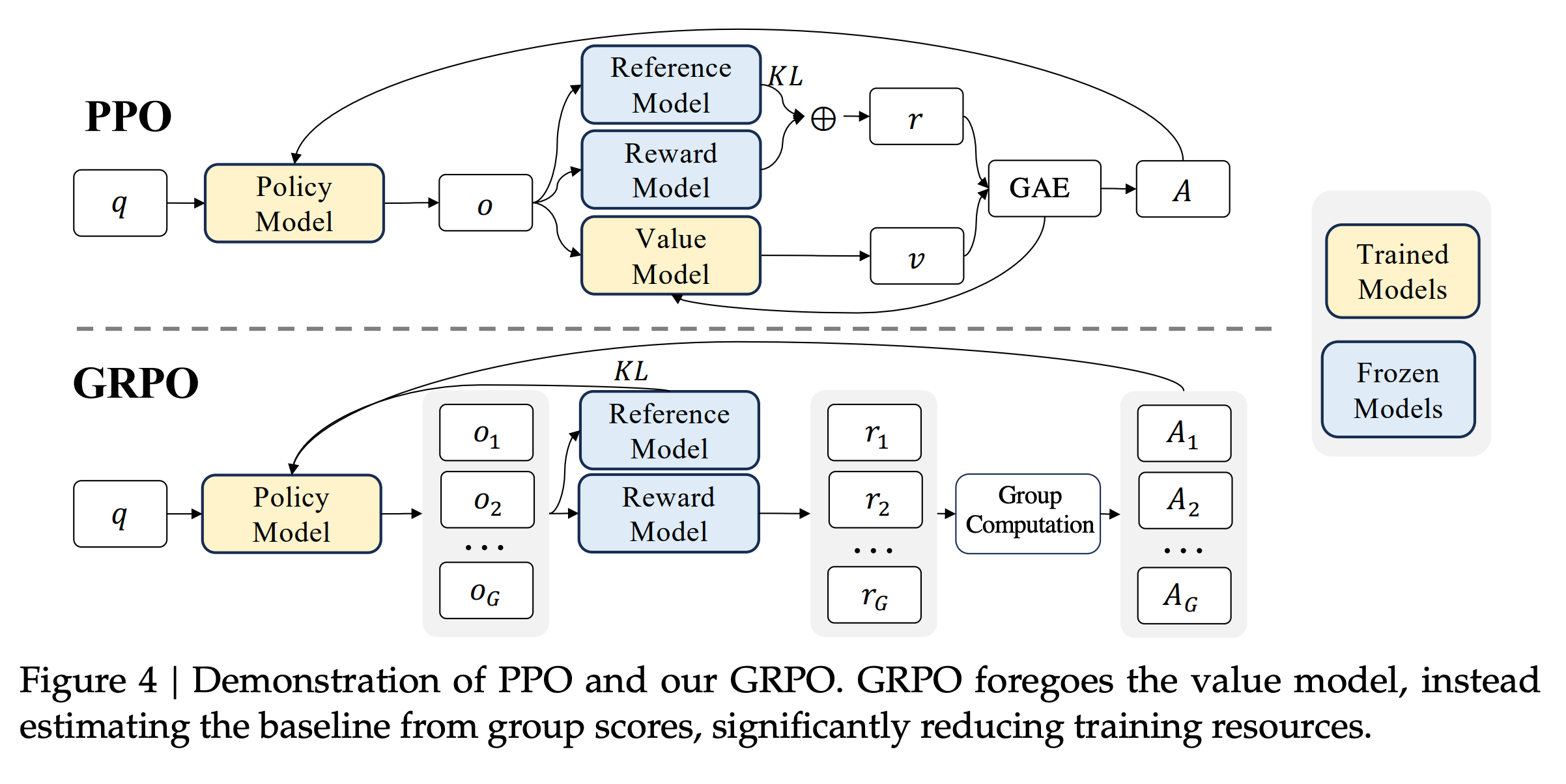
Instead of relying on a massive value network to estimate how good a state is, GRPO generates a group of responses to the same prompt and grades them on a curve against each other.
By dropping the critic, it slashes memory overhead and training costs drastically, making advanced RL accessible even on consumer hardware.
But as models scale, even vanilla GRPO shows some cracks.
Because it applies math at the individual token level rather than the sequence level, it can suffer from high-variance gradients and optimization biases—sometimes inadvertently teaching models to generate artificially long, rambling answers even when they are wrong.
In this article, we'll demystify GRPO from the ground up.
We'll look at how its group mechanism works, why its token-level math sometimes breaks down, and explore the cutting-edge variants—like GSPO, DAPO, and Dr. GRPO—that are fixing its flaws to make large-scale RL more stable and efficient than ever.
We'll keep the math light and focus on intuition.
Ready? Let’s go! 👇
The PPO Bottleneck
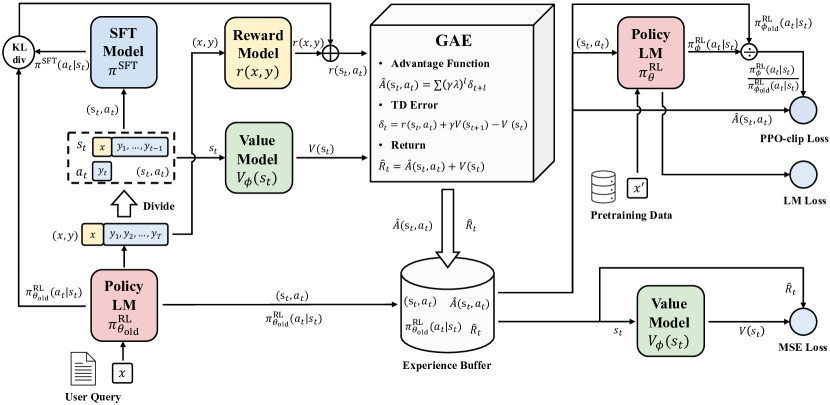
In our last exploration of the RLHF landscape, we crowned Proximal Policy Optimization (PPO) as the gold standard for online reinforcement learning.
However, implementing PPO at scale comes with a massive logistical headache: it requires maintaining four active models in your training pipeline simultaneously.
The real culprit of this computational burden is the value model, or the "critic", which exists to estimate how good a specific state or action is in order to guide the actor's learning.
Because this critic is typically a neural network of comparable size to the policy model itself, it effectively doubles your memory footprint and significantly bottlenecks training speed.
Beyond just the hardware tax, the critic faces a fundamental design friction when applied to large language models.
In traditional RL, the agent gets feedback at every step — move left, get a small reward, move right, get penalized.
The value function learns naturally because it has a dense stream of signal to work with. LLM post-training doesn't work that way. The reward typically arrives once, at the very end of the sequence:
Did the code compile or not?
Is the math answer correct or wrong?
…
Everything before that final judgment is a long chain of tokens with no intermediate score. Training a value function to be accurate at every individual token in that chain — when the only real signal comes at the end — is both incredibly difficult and wastefully expensive.
Faced with these computational and architectural burdens, researchers at DeepSeek—during the development of their DeepSeekMath and DeepSeek-R1 models—posed a radical question:
What if we didn't need a critic at all?
Their answer to this was Group Relative Policy Optimization (GRPO), an algorithmic breakthrough that completely eliminates the value model from the training pipeline.
By dropping the critic network entirely, GRPO simplifies the architecture and slashes memory overhead by 40% to 60% compared to traditional PPO.
The practical impact is hard to overstate. By cutting the critic, GRPO brings training costs down to roughly 1 / 18th of traditional RL methods.
That's the difference between needing a cluster and needing a single consumer GPU — teams have fine-tuned 1.5B parameter models with as little as 16GB of VRAM.
What used to require serious infrastructure is now something a solo developer can run on a desktop.
GRPO also turns out to be a natural fit for tasks with structured, verifiable rewards. Math, logic, code correctness — anything where you can definitively check whether the final answer is right.
In those settings, you don't need a critic estimating value at every token.
A binary signal at the end is enough, and GRPO is built to work with exactly that!
Inside GRPO
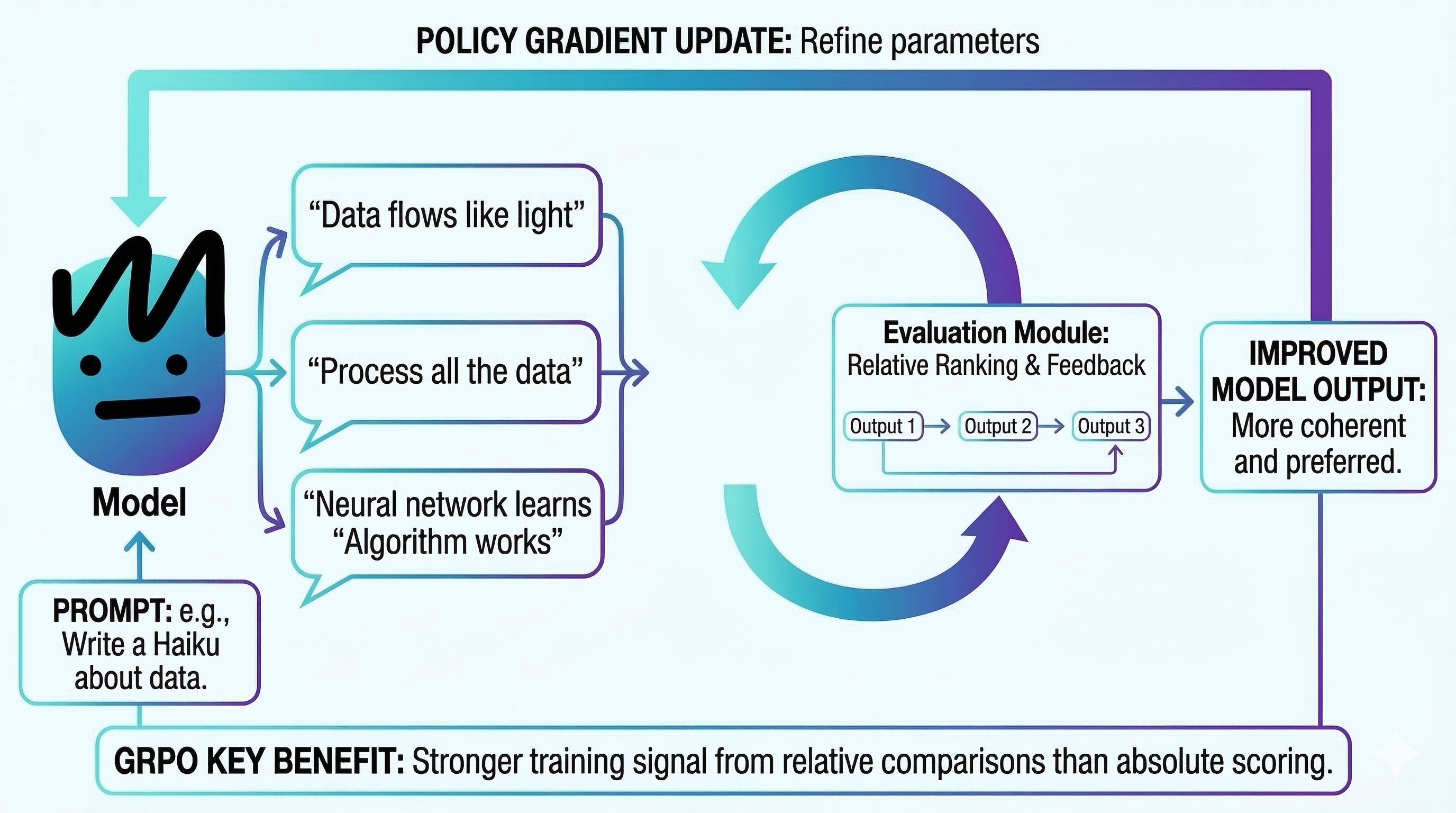
To understand how GRPO works without a value model, start with the "G" — the Group.
Rather than generating one response and asking a critic to judge it in isolation, GRPO generates multiple completions for the same prompt (typically 4 to 8) using the current policy. Then it compares them against each other.
Think of it as grading on a curve.
Each response gets scored — either by a reward model or a simple rule-based check like "is the math answer correct?" — and then GRPO calculates an advantage for each one.
The math is straightforward: take a response's score, subtract the group mean, and divide by the group's standard deviation.
Responses above the average get a positive advantage and are reinforced.
Responses below get a negative advantage and are suppressed.
No critic needed … the group itself is the baseline!
GRPO also makes a subtler but important architectural change to how it prevents the model from drifting too far from its original behavior.
In PPO, the KL divergence penalty — the term that keeps the policy from diverging from the reference model — gets baked directly into the reward. That means the advantage calculation is always entangled with the regularization signal.
GRPO separates the two cleanly: advantages are computed purely from relative performance within the group, and the KL penalty is applied independently in the loss function during the parameter update.
It's a small change on paper, but it gives the optimizer a much clearer learning signal.
If you want to build even stronger visual intuition for how GRPO works, we highly recommend this walkthrough by Luis Serrano! 👇
The Cracks in GRPO
GRPO's elegance starts to crack at scale, and the root cause sits in the math powering its updates: importance sampling.
Generating responses from large language models is expensive, so RL algorithms avoid sampling fresh outputs for every gradient step.
Instead, they reuse responses from a previous version of the policy and apply a correction factor — the importance ratio — which measures how likely the current policy would have been to produce each token compared to the old one.
When the two policies are close, this correction works well. But as training progresses and the model drifts from its earlier self, these ratios can spike or collapse unpredictably, injecting massive variance into the gradient estimates.
GRPO makes this worse through a fundamental mismatch in granularity.
The reward is assigned at the sequence level — did the model get the final answer right? — but importance sampling corrections are applied at the token level.
Over a long reasoning chain spanning hundreds or thousands of tokens, those token-level ratios multiply together. A single unstable token probability can warp the learning signal for the entire sequence. This is especially damaging in Mixture-of-Experts (MoE) architectures, where different tokens may route through entirely different experts, making the ratio between old and new policies even more volatile.
On top of the variance problem, GRPO's formula introduces two optimization biases that quietly steer training in the wrong direction.
The first is length bias: GRPO averages the loss across the number of tokens in a response. That sounds reasonable, but it creates a perverse incentive. A short wrong answer gets heavily penalized per token. A long wrong answer — say 2,000 tokens of rambling — spreads that same penalty thin. The model learns, over time, that when it doesn't know the answer, it's better off being verbose!. Wrong but long gets punished less than wrong but concise.
The second is difficulty bias: GRPO normalizes advantages by dividing by the group's standard deviation. For most prompts this works fine, but it breaks down at the extremes. If a question is so easy that every response in the group gets it right, or so hard that every response fails, the standard deviation collapses toward zero. Dividing by a near-zero number causes gradient weights to explode, which means the model over-indexes on trivially easy and impossibly hard questions — exactly the ones where there’s the least to learn — while underweighting the middle range where meaningful improvement actually happens.
Beyond GRPO …
While GRPO successfully democratized large-scale alignment by eliminating the memory-heavy critic model, its architectural quirks become undeniable bottlenecks when applied to massive reasoning models.
As models scale, the token-level mathematics of GRPO introduce compounding variance, optimization biases, and severe instabilities that can sometimes lead to irreversible model collapse.
To address these friction points, the AI research community has rapidly developed a new generation of optimizers—most notably DAPO, GSPO, and Dr. GRPO—that refine and stabilize the group-relative learning process.
Dynamic Advantage Policy Optimization (DAPO)
Dynamic Advantage Policy Optimization (DAPO) addresses the practical inefficiencies and wasted learning signals often observed during GRPO training.
One of DAPO's key interventions is Token-Level Gradient Loss, which fixes the mathematical quirk where gradient weights for individual tokens artificially decrease as a generated response gets longer.
By averaging the loss over the total number of generated tokens rather than at the sample level, DAPO ensures that complex, lengthy reasoning paths do not dilute the learning signal.
Furthermore, DAPO introduces Overlong Reward Shaping, a soft penalty mechanism that prevents the model from gaming the system with excessive verbosity by progressively punishing responses that exceed defined length thresholds without reaching a correct conclusion.
To further combat training instability, DAPO modifies how policies are clipped and sampled. It implements "Clip-Higher", an asymmetric clipping strategy that gives more breathing room for promising, low-probability tokens to increase in likelihood without hitting an artificial ceiling too early.
Additionally, DAPO enforces Dynamic Sampling by ensuring that every evaluated group contains at least one correct and one incorrect response. This structural constraint prevents the massive computation waste that occurs in vanilla GRPO when a group of uniformly right or wrong answers yields an advantage of zero and, consequently, zero gradient.
Group Sequence Policy Optimization (GSPO)

Group Sequence Policy Optimization (GSPO) takes a more fundamental mathematical approach by directly fixing the unit mismatch inherent in GRPO.
Traditional GRPO evaluates success based on the final sequence but applies importance sampling updates at the individual token level, which creates explosive variance and structural noise in long reasoning tasks.
GSPO resolves this by shifting the optimization granularity to the sequence level.
It redefines the importance ratio based on sequence likelihood, computing the geometric mean of token-level ratios to create a single, stable weight applied uniformly across the entire sequence.
This perfectly aligns the sequence-level optimization target with the sequence-level reward.
This sequence-level shift in GSPO has proven especially revolutionary for Mixture-of-Experts (MoE) architectures. In standard GRPO, the dynamic nature of MoE routing causes expert activation volatility, meaning new and old policies might activate completely different experts, triggering abnormal clipping and training collapse.
Previously, this required a heavy workaround called "Routing Replay" to freeze expert paths during training, which increased memory and communication overhead.
Because GSPO evaluates the likelihood of the sequence as a whole rather than specific token-routing paths, it completely eliminates the dependency on Routing Replay, stabilizing MoE training natively while allowing models to maximize their capacity.
Dr. GRPO (GRPO Done Right)
Finally, Dr. GRPO (GRPO Done Right) offers a minimalist, unbiased correction to the original formula. Researchers identified that GRPO's mathematical practice of normalizing advantages by both the response length and the group's standard deviation creates a severe optimization bias.
Specifically, dividing by sequence length inadvertently penalizes longer incorrect responses less than short ones, which causes the policy to prefer lengthier responses among incorrect ones and teaches the model to ramble when it is wrong.
Dr. GRPO simply removes these two normalization terms, producing an unbiased estimator that halts the runaway growth of incorrect response lengths and dramatically improves overall token efficiency.
Next Steps

Remember that this Friday we'll move from theory to practice in our hands-on lab.
See you there builder! 👋