

The future of Video Search is here
How we built a Video-RAG system that makes your videos instantly searchable


Have you ever dreamed of a system that truly understands what’s happening in a video?
Not one that spits out a vague summary, but one that can tell you the color of the main character’s shirt, how many glasses are on the kitchen counter, or even the exact date on a calendar in the background.
Picture this: you want that one iconic scene from a movie — you ask for it, and within seconds, you’ve got the exact clip you were looking for.
I know what you’re thinking:
“Okay, that sounds incredible… but it must cost a fortune, right?”
What’s the point of having something this powerful if you’d have to remortgage your house just to use it?
Relax … no remortgaging required 😅
Today,
and I want to show you how we built our own Video Processing Agent: Kubrick.It’s all powered by a technique called Video-RAG, inspired by the paper “Video-RAG: Visually-aligned Retrieval-Augmented Long Video Comprehension”.

Here’s the simple idea behind it:
Instead of fine-tuning a massive vision-language model on the entire video all at once, why not turn it into a retrieval problem?
We took that concept and … gave it a twist, (semantically) representing each video using its audio, frames, and captions.
Pretty cool, right? So let’s not waste any more time.
Here’s how our Video-RAG works under the hood! 👇
💡 Kubrick is a collaboration between
and . If you’d like to follow along week by week, check out our code repository, drop us a star, and stay tuned for upcoming articles (and videos 😉)!
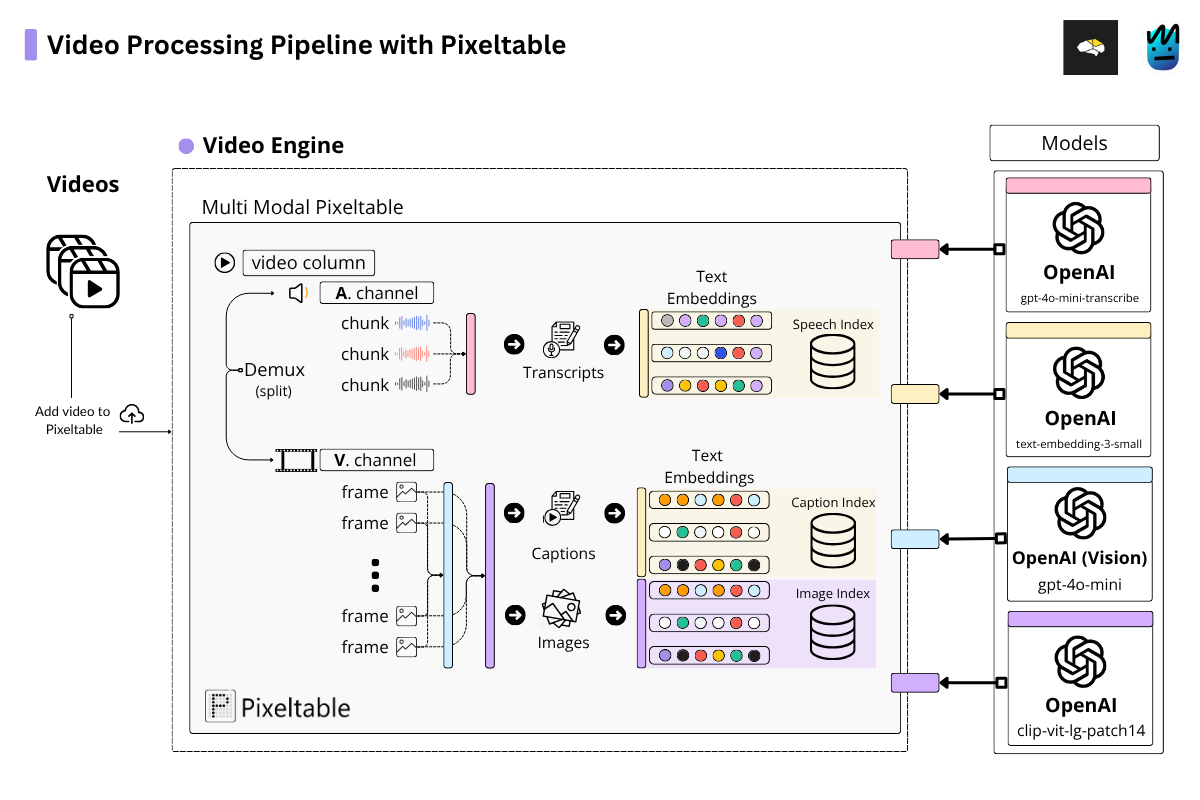
Video-RAG with Pixeltable
You’re probably wondering what I mean when I say we “semantically” represent a video, right?
Think about a PDF you want an LLM to understand. What do we do? We split it into chunks, turn those chunks into embeddings, and store them in an embedding index. Makes sense, right?
Well, with a video, the idea is the same — but “chopping” up a video into chunks doesn’t really work the same way. We have to handle the audio and frames differently.
The audio gets transcribed into text, then chunked and stored in its own index as embeddings.
The frames? Same deal — we sample them and create two separate indexes: one with embeddings of the raw frames, and another with embeddings of the captions (both using CLIP embeddings).
“But Miguel, are you insane? Did you implement all the operations to extract audio, sample video frames, transcribe the audio…?”
No way! That’s where Pixeltable comes in 😎
A Python library designed exactly for multimodal systems like ours.
It lets you build robust multimodal ETL pipelines in just a few lines of code. Plus, it has built-in support for creating vector databases for semantic search (not to mention the parallelization, caching, lineage tracking, etc.; all out of the box!).
Now that we know why Pixeltable is useful, let’s take a look at how it works in practice.
Creating the Transcripts Index
Processing with Pixeltable starts the moment we upload a video. The first thing our system does is handle the audio, following the steps shown in the snippet below.

The last step extracts the text from the transcriptions generated by gpt-4o-mini-transcribe.
We’ll use this text to create our embedding index, as you can see below. With Pixeltable, it’s possible to create an index in just a few lines of code!
Creating the Images (Frames) Index
Now that we’ve processed the audio, it’s time to do the same with the frames.
For this, we’ll use Pixeltable’s FrameIterator, which lets us sample video frames at a constant FPS — and we can tweak that FPS however we want.
💡 We can also set a fixed total number of frames to keep costs reasonable for very long videos.

Once we have each frame, we use CLIP as our embedding model and create another embedding index.
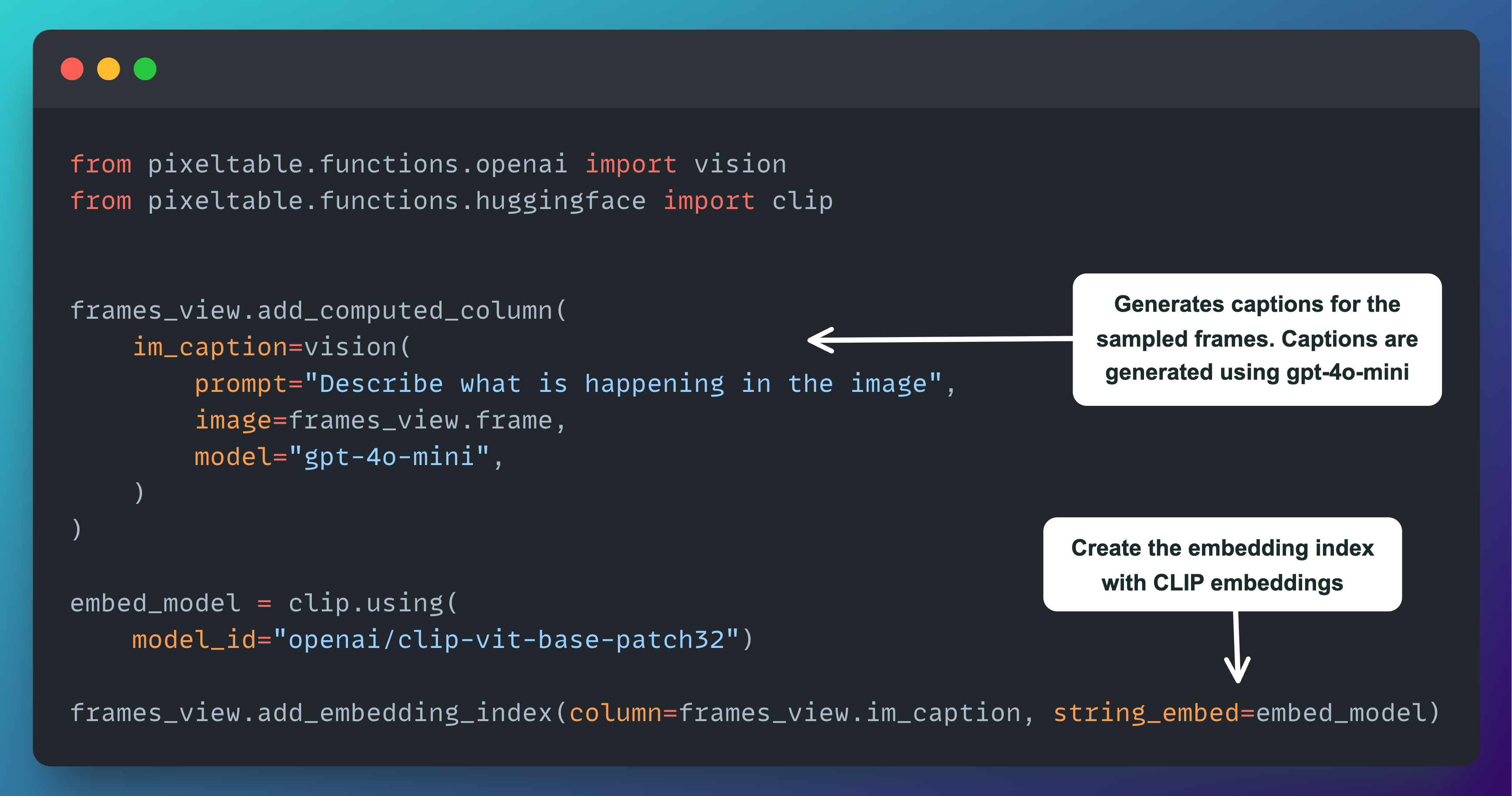
Creating the Captions Index
As I mentioned earlier, we need two embedding indices: one for the frames (images) and another for the captions of those frames.
That’s exactly what we’re doing in this last code snippet — using gpt-4o-mini to analyze and describe each frame, then turning those captions (text) into embeddings with CLIP and storing them in their own index.
Right now, we already have three embedding indices in our system: one for the audio transcriptions, one for the frames, and one for the captions of those frames.
And now you’re probably thinking… “Okay, but what do I do with all this?”
Well, you’ll have to wait until next Wednesday to find out! Although I bet you can guess — because the next article is all about the retrieval phase (the fun part).
But hey, I’m not that mean — I don’t want to leave you hanging completely. So, let me show you what happens if I take a video like this one (The Shining) …
… and run it through Kubrick, asking the system to show me the iconic “Here’s Johnny!” scene from The Shining. Voilá.
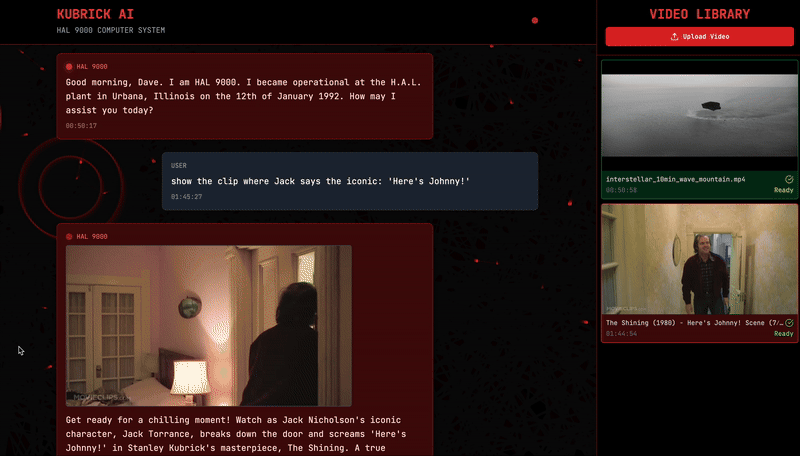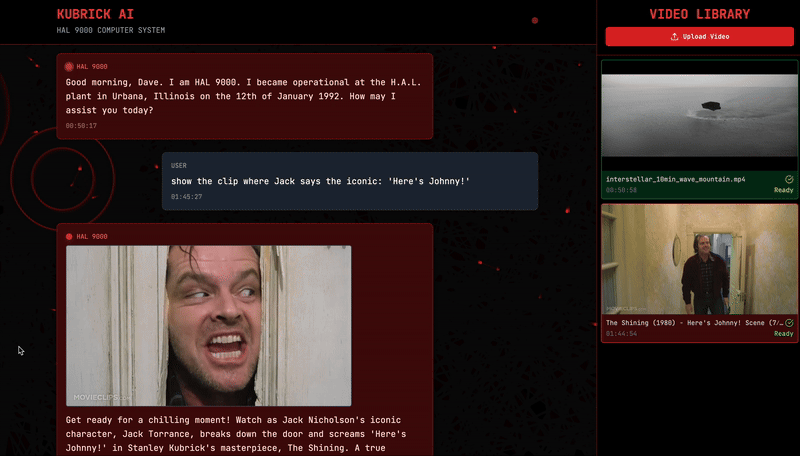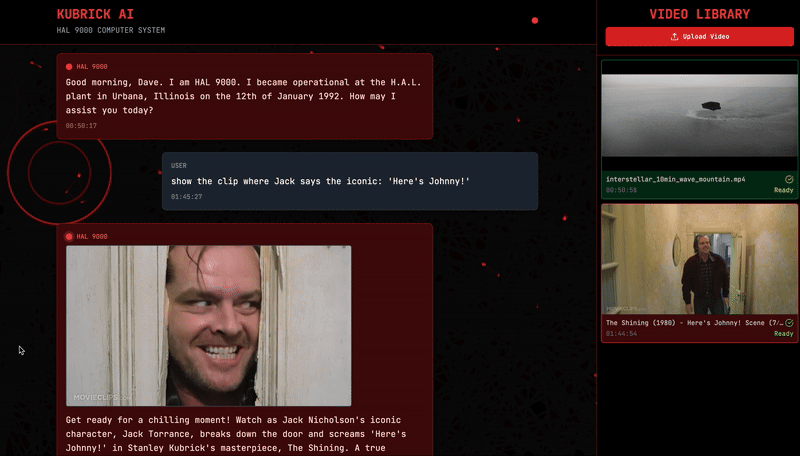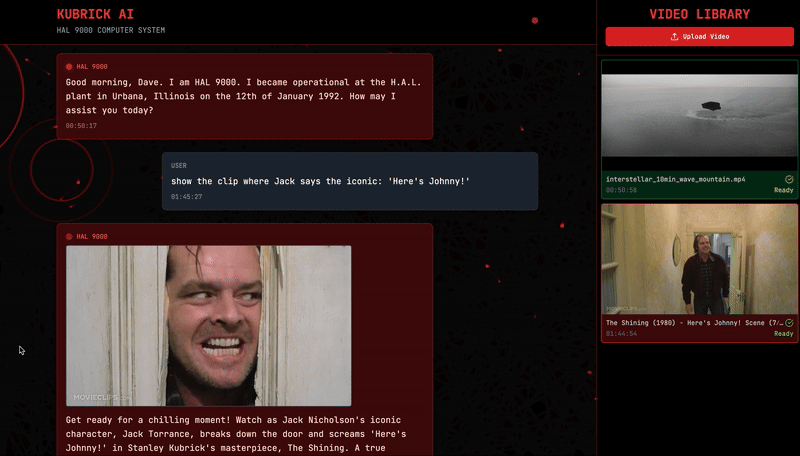
What’s happening behind the scenes? Kubrick is just doing a retrieval on the audio transcription embedding index!
We could try the same with this masterpiece from Interstellar…
… and then ask Kubrick for that scene with the spaceship “surfing” the giant tsunami wave. Bingo! This time, Kubrick is using the caption index!

And that’s it! Don’t ask me for more examples 🤣
You’ll have to wait until next Wednesday. This Saturday, Alex will share his own piece on Kubrick in
, where he’ll go deeper into VLMs and other things I couldn’t fully unpack here. So stay tuned!See you soon, builders! 🫶
Thank you, learned about Pixeltable today
Nice. And what will be the cost of 2 hour movie? My estimate with 0.5 second frame capture is about 1.5$