

The Engineer's Guide to Supervised Finetuning
Finetuning Sessions · Lesson 2 / 8


Welcome to Lesson 2 of the Finetuning Sessions!
Before we jump into the lab this Friday, let's zoom out for a minute. Supervised Fine-Tuning (SFT) isn't about adding more knowledge to a model. It's about changing how the model behaves!
🙋 We're not filling it with new facts, we're teaching it how to respond in a structured way.
That's what this lesson is about.
We'll walk through how a model moves from basic pre-training (just predicting the next token in a long stream of text) to structured conversation. By the end, you'll have a clear and simple mental model of what's actually changing.
A lot of teams get confused because they treat SFT like a black box. But once you understand the mechanics it all starts to click! The model doesn't just "chat" better…
📘 It learns to respond with structure and intention.
Alright, no more buildup. Let's get started!
SFT: A high-level intuition
We often picture LLMs reading the way we do — moving through a sentence, pausing at a word, attaching meaning, slowly building up understanding.
❌ That image feels natural … but it's also wrong.
What's actually happening is much more mechanical. A model processes text as a stream of tokens, one after another. There's no inner voice, no quiet moment of reflection. Just pattern recognition running across a sequence.
During Continued Pretraining (CPT), the system is exposed to an enormous, uninterrupted flow of language — books, articles, forums, code — all blended into one massive signal.
Over time, patterns begin to settle in. Certain tokens cluster together. Scientific writing develops one statistical fingerprint; poetry develops another. "Quantum" frequently sits next to "physics" — not because there's comprehension, but because the pairing shows up often enough to become predictable.
At that stage, the model is excellent at continuing text. What's missing is the structure of interaction…
🙋 There's no natural sense of where a question ends, where a response begins, or whose turn it is.
That's the gap Supervised Finetuning (SFT) fills!
If pre-training teaches the model the general patterns of language, SFT teaches it structure. It introduces roles, boundaries, and turn-taking. It makes clear what is input and what is response.
Special tokens mark where the user finishes and where the assistant should begin. Those markers aren't natural language, but they're structurally powerful. They act like cues in a performance: "Now it's your turn. Now respond!"
🙋 Without that training, the model doesn't know when to stop continuing the user's thought!
And once the model internalizes that rhythm, something subtle but important happens. It stops behaving like a text completion engine and starts behaving like a participant.
That's the real shift!
The Jinja2 "Skeleton"
🤔 Where does "I" end and "you" begin inside a transformer?
At the raw level, there is no built-in concept of speaker or listener. There are only tokens flowing through attention layers.
That's why the chat template exists!
A chat template is the translation layer between our clean Python list of {role: ..., content: ...} messages and the single flattened string the model actually sees. It's the scaffolding of the conversation. Without it, everything collapses into one undifferentiated stream.
Modern templates have become very explicit about structure. When you see something like:
<|start_header_id|>user<|end_header_id|>that's not just a label.
It's a structural signal that tells the model, "This segment belongs to the user."
The model has learned to associate that pattern with a specific behavioral state. The same goes for reasoning markers like <think> and </think>. Those tags aren't decorative — they carve out a protected space for internal reasoning before producing an outward response.
🙋 We'll cover Chat Templates in much more detail in this Friday Lab!
Under the hood, these templates usually live inside tokenizer_config.json, often written in Jinja2. And this is where teams frequently get into trouble.
If you fine-tune a model with one template but deploy it with another, the structure shifts under its feet.
It's like teaching someone to play in one rhythm and then changing the time signature during performance. The symptoms show up quickly: confused responses, broken tool calls, the model answering on behalf of the user because it no longer recognizes the end-of-turn signal.
Once you start introducing tokens like <|tool_call|> and <|tool_response|>, the structure becomes even more important. Now the conversation isn't just text — it's text with architectural zones.
Some segments represent user intent. Others represent the assistant's voice. Others represent API interactions. Each carries a different role in the exchange.
The chat template is what makes all of that legible to the model.
📘 You can check this simple introduction in Hugging Face docs for more examples.
SFT vs. CPT
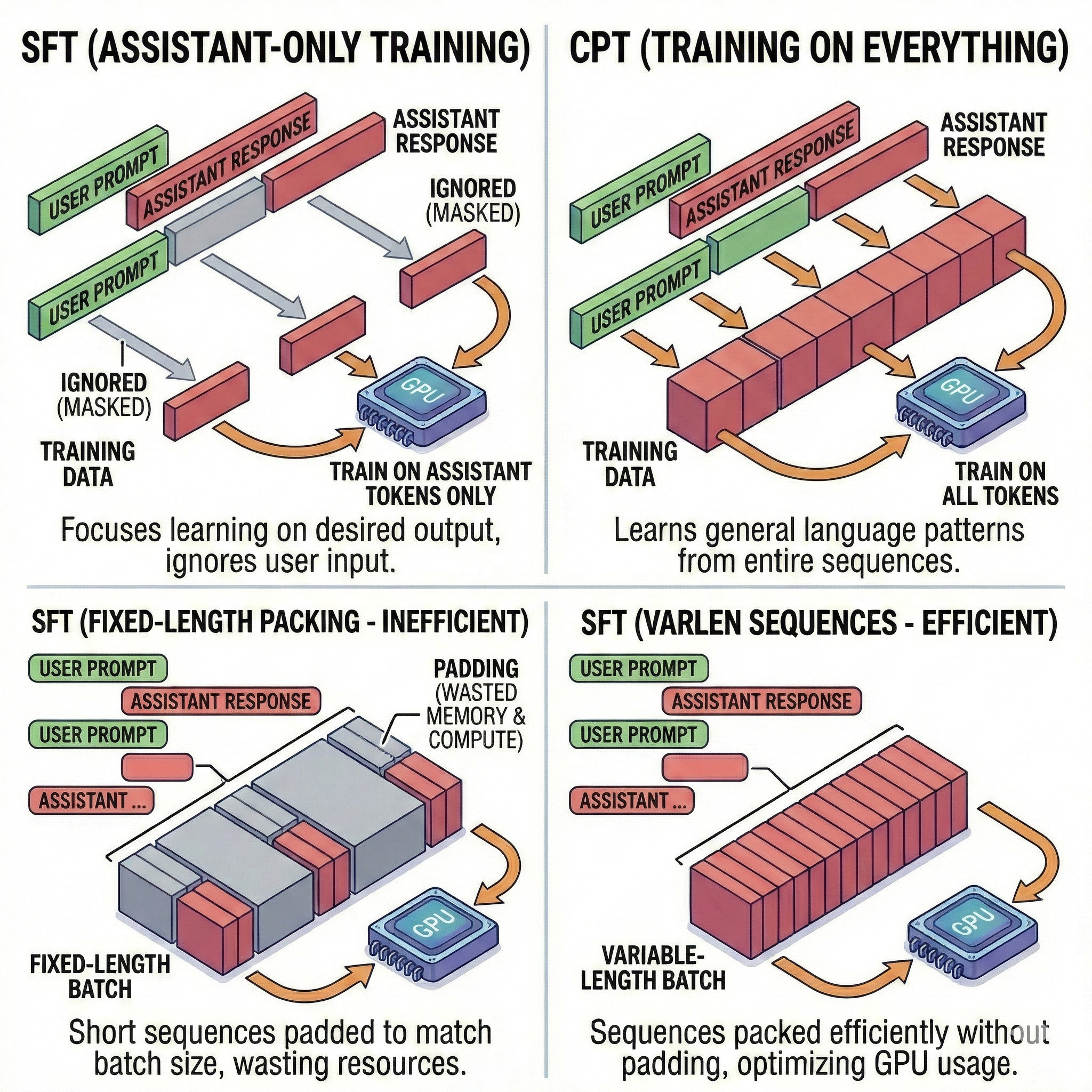
The distinction between Continued Pretraining (CPT) and Supervised Finetuning (SFT) is often described as a difference in data, but it is more accurately a difference in consumption.
CPT is a "buffet" where the model eats everything in sight to maximize throughput. The goal is to maximize the amount of knowledge the model can absorb per FLOP.
In contrast, SFT is a "multi-course meal"—the order of the dishes, the cleanliness of the plates, and the boundaries between courses are the entire point of the exercise.
🙋 The most critical technical divergence here is "Loss Masking".
During CPT, the model calculates a loss (a penalty for being wrong) on every single token in the sequence.
In SFT, we typically compute the loss only on the Assistant's tokens. We achieve this by setting the labels for User tokens to -100.
In PyTorch’s CrossEntropyLoss, -100 is the ignore_index. This sends a specific command to the optimizer: "Process the User's prompt to understand the context, but do not try to learn how to predict it. Only learn how to respond."
This leads us to the "Packing Paradox"!
In CPT, we use "Packing" to concatenate multiple documents into a single 8k or 128k context window to keep the GPUs saturated.
However, in SFT, standard packing can cause "cross-contamination". If the end of one conversation and the start of another are packed too tightly without proper masking, the model's attention can leak, leading it to confuse the context of the first dialogue with the requirements of the second.
To solve this, modern trainers have moved toward "Padding-Free" SFT using Flash Attention 2 and Variable Length (Varlen) sequences.
Instead of padding out short conversations with useless zeros—which wastes compute—tools like Hugging Face TRL or Unsloth pass a cu_seqlens (cumulative sequence lengths) tensor.
This allows the GPU to process a batch containing multiple conversations of different lengths simultaneously, while maintaining a hard firewall between them.
It is the technical realization of the "multi-course meal": efficiency without flavor contamination 🍲
The Taxonomy of Training
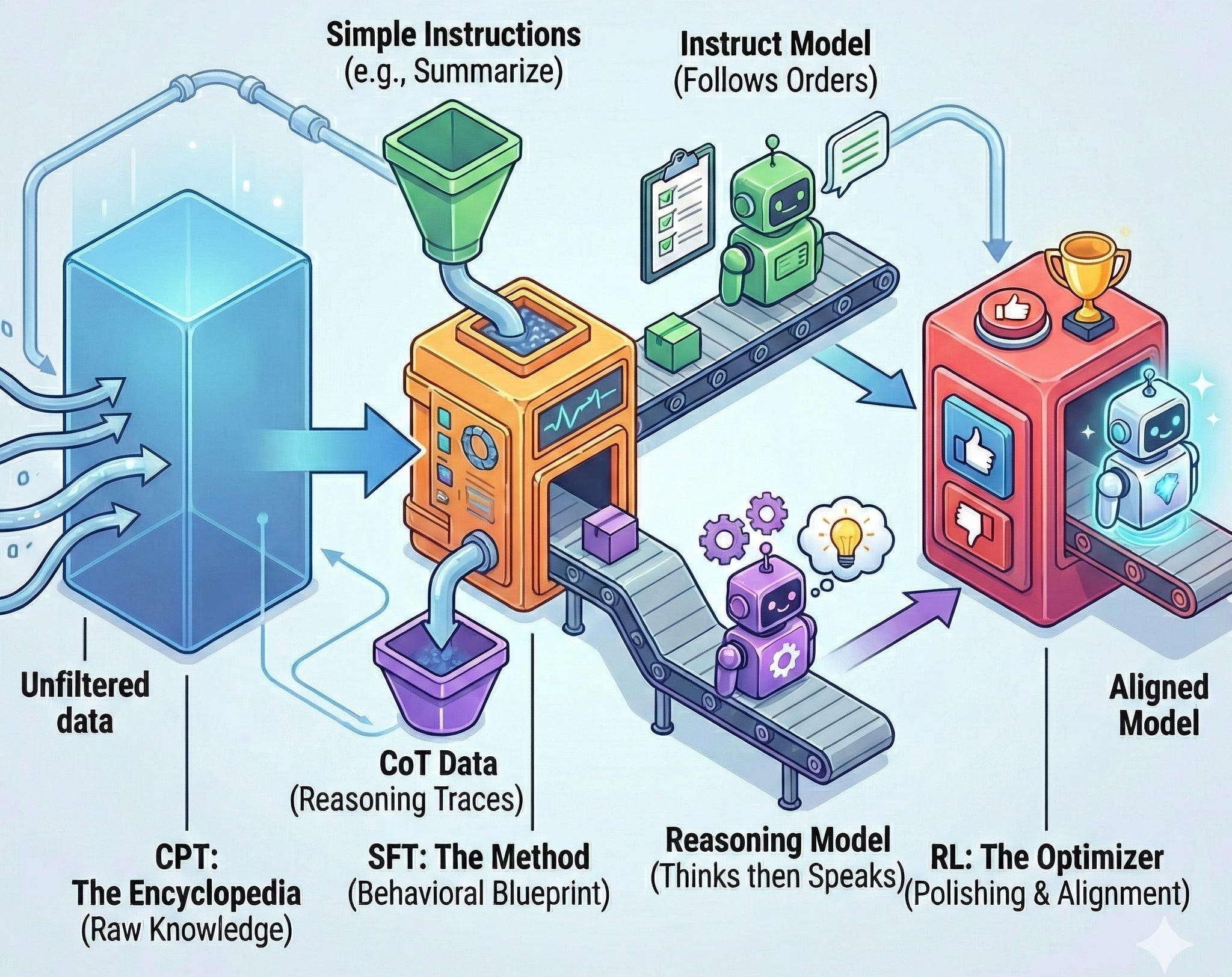
In a lot of AI conversations, product labels get mixed up with technical reality.
We talk about "Instruct Models" and "Reasoning Models" as if they're different species! They're not.
SFT isn't a type of model. It's a training step. A tool.
What it does is simple in principle: it teaches a model to map a certain kind of input to a certain kind of output.
If the training data contains short, direct answers, the model learns to produce short, direct answers. If it contains long chains of reasoning, the model learns to produce long chains of reasoning. The difference comes from the data, not from some new underlying algorithm.
Another common misconception is that Reinforcement Learning is the magic ingredient that suddenly makes a model "think".
That framing misses how the pipeline actually works!
SFT is what gives the model the structure of reasoning. It exposes the system to examples of how problems are broken down, how logic flows, how answers are structured. In other words, SFT teaches the model what reasoning looks like.
Reinforcement Learning comes later.
Its role isn't to invent reasoning from scratch — it's to reinforce good behavior and discourage bad shortcuts. It nudges the model toward clearer, more truthful, more efficient responses. But if the model never saw structured reasoning during SFT, there's nothing for RL to refine.
A good example is DeepSeek-R1. Before applying RL, the team ran a "cold start" SFT phase on high-quality Chain-of-Thought (CoT) data. That phase seeded the behavior of step-by-step reasoning. Only after that foundation was in place did RL step in to reward consistency and penalize weak logic.
It's helpful to think of the training process as layers.
Continued Pretraining (CPT) builds broad knowledge — the encyclopedia.
SFT shapes behavior — the persona and the conversational rules.
RL refines alignment — encouraging accuracy, coherence, and preference matching.
Each stage builds on the previous one. Together, they move the system from raw statistical patterns toward structured, aligned behavior.
Data Curation: The LIMA Hypothesis
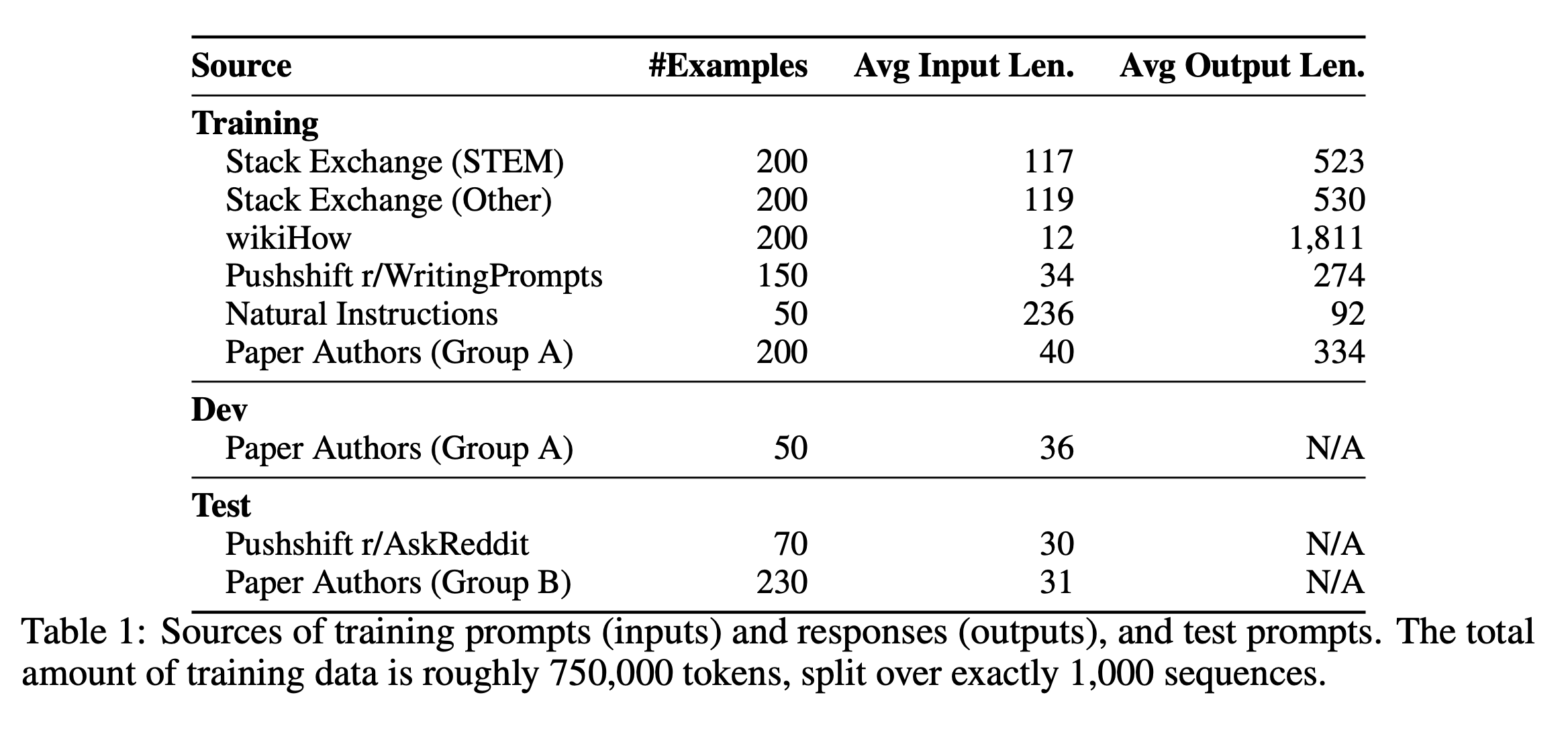
If the CPT phase was about scale, the SFT phase is about precision.
For a long time, the assumption was simple: more data equals better models. Bigger datasets, broader coverage, more examples — that was the formula.
But research like LIMA (Less Is More for Aligment) challenged that idea. It showed something uncomfortable: a model fine-tuned on around a thousand carefully curated, high-quality examples could outperform models trained on tens of thousands of noisy ones!
And that shift has changed the role of the AI engineer.
The job is no longer just watching loss curves drop. It's about designing the right data mixture. Think of it less like data collection and more like composition.
A strong SFT dataset is balanced: some mathematical reasoning to sharpen logic, some high-quality code to reinforce structure, conversational examples to shape tone and persona, safety-aligned samples to anchor behavior.
The mix matters! Why? Because SFT is sensitive. The model doesn't just absorb facts during fine-tuning — it absorbs patterns of behavior. If the dataset contains sloppy reasoning, inconsistent formatting, or vague answers, those patterns become normalized. The model treats them as the standard.
That’s why many labs have moved away from large, scraped instruction datasets and toward synthetic pipelines. Instead of collecting whatever is available, they generate high-quality examples using strong teacher models, then filter aggressively.
The goal isn't quantity, but density — packing each example with as much useful structure and clarity as possible.
The "Thinking" SFT
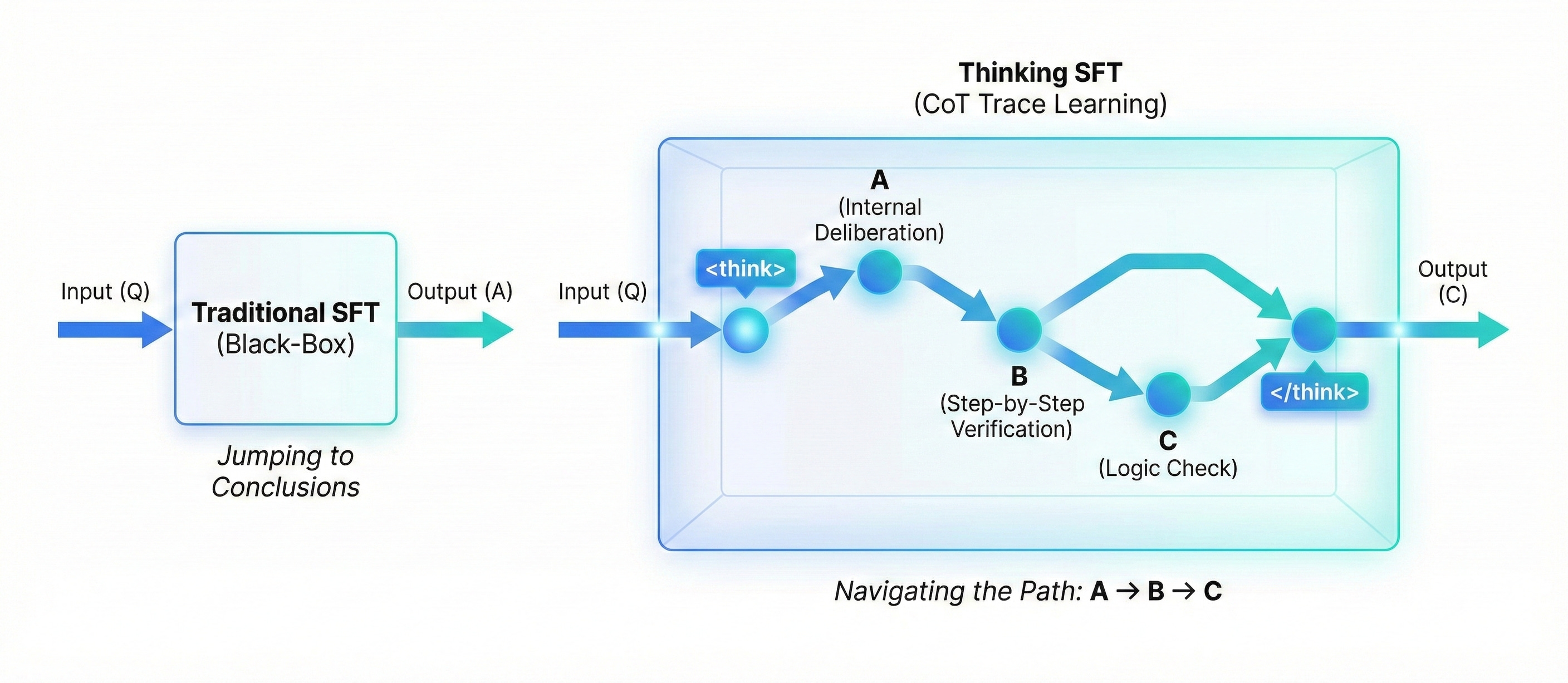
Traditional SFT was straightforward: a question goes in, an answer comes out.
The model learns to map input directly to output. For many tasks, that works. But it also encourages shortcutting. If the model can jump straight from A to C, it will — even when it shouldn't! And that's where hallucinations creep in.
Reasoning-focused SFT changes that pattern.
Instead of training the jump from A → C, we train the full path: A → B → C. That middle step — B — is the reasoning trace. The step-by-step breakdown. The visible thinking process.
These traces are essentially worked solutions. They show how a problem unfolds, not just how it ends. When a model is finetuned on that structure, something subtle shifts. It stops treating the answer as the only objective and starts modeling the process that leads there.
The use of tags like <think> creates a defined space for that process. Structurally, it separates internal reasoning from the final response. The model learns that before producing the answer, there's a phase dedicated to working things out.
The key insight — and this was central in systems like DeepSeek-R1 — is that you can't expect reinforcement learning to invent this behavior from scratch!
The search space is simply too large. Without examples of structured reasoning, the model has no template to optimize. It wanders.
So the reasoning habit has to be seeded first. SFT provides that template. It shows what good step-by-step thinking looks like. Once that pattern exists, reinforcement learning can refine it — rewarding correct derivations, discouraging shortcuts.
That procedural layer — that habit of working through a problem — is what turns a basic instruction model into something capable of sustained reasoning.
🧪 In this Friday's lab, we'll finetune two models on the same dataset — one with reasoning traces, one without. You'll see the difference immediately: one actually reasons through the problem, the other just jumps to the answer.
Masking, Padding, and the "Shift-Right"
At the implementation level, SFT demands much more precision than CPT.
One of the most common engineering challenges is teaching the model what not to learn from. During finetuning, we don’t want the model to predict the user's question — only the assistant's response. That's handled in the data collation step.
Using a DataCollator, we create a labels tensor that mirrors the input_ids, but with a twist: every token belonging to the System or User roles is replaced with -100. In PyTorch, -100 tells the loss function to ignore those positions. As a result, only the assistant's tokens contribute to the gradient update.
A small detail here matters a lot: causal language models use a shift-right setup.
They always predict the next token. So the loss on the final token of the user's prompt is actually tied to the model's ability to predict the first token of the assistant's reply. That boundary — the exact transition from user to assistant — is where the model learns how to begin responding. If your masking is off by even one token, response initiation can break in subtle ways.
Batching introduces another layer of trade-offs.
In CPT, constant packing is common. You fill the context window aggressively to maximize GPU utilization, even if it means stitching unrelated sequences together. In SFT, that's risky. Conversations have boundaries that must be preserved.
So instead, grouped batching is often used. Sequences of similar lengths are batched together to reduce padding while keeping conversations intact. You sacrifice a bit of throughput, but you protect structural integrity — and avoid the model blending the end of one dialogue into the start of another.
Finally, there's the issue of gradient spikes.
Because the training signal abruptly switches from ignored tokens (-100) to active assistant labels, the first few assistant tokens often carry disproportionately high loss. That sudden transition can destabilize training early on. To manage this, many SFT setups use a lower learning rate or a warm-up schedule.
The goal is to ease the model into those boundary updates without shaking the weights too aggressively.
Agentic SFT: Learning to Use Tools
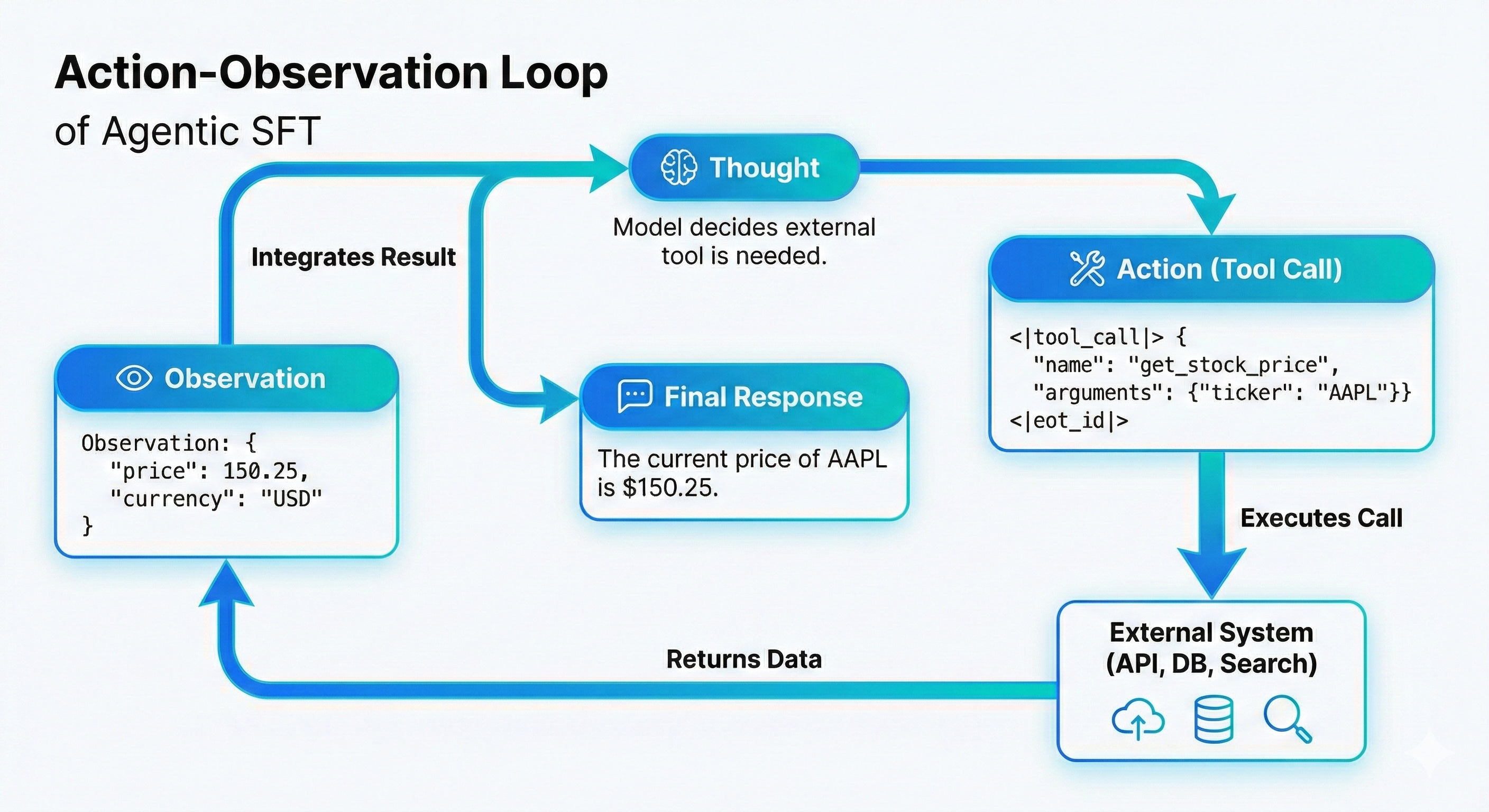
SFT isn't only about teaching a model how to speak. It's also how we teach it how to do things.
Agentic SFT is the step where the model gets "hands". Instead of just answering questions, it learns to recognize when a task requires an external tool — a database query, a search request, an API call.
To train that behavior, the data has to reflect it!
An agentic dataset follows a structured loop:
Thought → Action → Action Input → Observation → Final Response.The model first reasons about what to do. Then it generates a tool call — often in strict JSON format. At that point, generation pauses. The system executes the tool. The result (the observation) is fed back in. Only then does the model produce its final answer.
This is no longer just about meaning. It’s about format discipline.
If the model forgets a bracket in the JSON, the tool call fails. The agent breaks. So during fine-tuning, syntax becomes just as important as content. The model must treat structure as non-negotiable.
That's why Agentic SFT often relies on very clean, carefully constructed tool-calling traces — frequently synthetic ones. The goal is consistency. You want the model to internalize the exact schema it must follow. Without that rigor, a model might realize it needs a tool, but still generate a malformed call that never executes.
The model learns that it doesn't know everything. It may not know the current stock price — but it knows how to produce the precise sequence required to request it:
<|tool_call|> get_stock_price {"ticker": "AAPL"} <|eot_id|>That shift, from answering everything internally to coordinating with external systems, changes the role of the model entirely.
Instead of a closed knowledge system, it becomes part of a larger loop — an agent operating within an environment.
And that's a major evolution in how these systems are built and deployed today!
Evaluation
In the CPT world, evaluation is simple: watch the loss. If perplexity drops, the model improves. Lower loss means better next-token prediction.
SFT isn't that straightforward.
When fine-tuning for behavior, a very low loss can actually be a warning sign. It may mean the model has overfit to the exact wording of the training set. Instead of learning how to respond well, it memorizes phrasing.
You don't get a smarter model … you get a polished parrot 🦜
Because of that, the industry has shifted how it evaluates SFT.
Raw loss is no longer the main signal. Instead, teams rely on reward-style benchmarks and LLM-as-a-judge setups. A stronger "teacher" model grades the outputs — scoring clarity, tone, helpfulness, constraint-following.
The goal isn't to check whether the model reproduced training tokens. It's to see whether it captured the intent behind them.
Instruction-following benchmarks like IFEval (Instruction Following Evaluation) play an important role here. These tests impose strict constraints — for example, writing within a word limit or avoiding specific letters. They force the model to balance natural language fluency with rule compliance. Passing them shows that the finetuning reshaped priorities, not just surface patterns.
Now, with agentic systems, the bar is even higher. It's not enough to follow instructions in a single response. Models are evaluated on multi-step, real-world tasks. This has given rise to benchmarks such as:
GAIA (General AI Assistants): Unlike traditional benchmarks that focus on linguistic puzzles, GAIA tasks models with everyday assistant tasks—like booking a flight or finding a specific data point in a PDF—that require tool use and multi-modality.
SWE-bench: This evaluates the model’s ability to act as a Software Engineer by tasking it to resolve real GitHub issues. It measures whether the agent can navigate a codebase, understand an issue, and provide a functional code patch that passes unit tests.
WebShop / Mind2Web: these focus on web navigation, testing if an agent can autonomously use a browser to achieve a goal, such as purchasing a specific item under a certain budget.
📘 Take a look at extensive leaderboards here!
In conclusion, evaluating SFT is about measuring alignment, not just accuracy. It's about ensuring that the model's internal probability distribution has been reshaped to favor helpfulness, honesty, and harmlessness.
When the loss curve flattens in SFT, the real work is just beginning. We must look past the numbers and into the behavioral blueprint we have created, ensuring the model isn't just reciting a script, but has truly learned the rhythm of human interaction.
Next Steps

That's a wrap for today's article!
We've covered the intuition, the structure, and the moving pieces behind SFT. Now it’s time to move from theory to practice.
We'll meet again this Friday in the hands-on lab, where we'll:
Break down chat templates in detail — with special focus on the Qwen3 chat template
Fine-tune two models: one with reasoning traces and one without
Give you access to the synthetic dataset we've created so you can experiment yourself
Deploy both models
Evaluate them using Comet and compare their behavior side by side
See you there! 👋
This document is gold , it actually mentions the less talked about nuances in the AI world.
1.Why packing is not suited to SFT and how unsloth and Flash attention 2 resolve it
2.tokenizer_config.json has the chat template (i remember always searching docs for it for every model)
3.Think SFT explaination of taking the shortcuts (diagrams are gold here)
4.The System/User doesnt get trained on by assigned it a with -100 input_id which pytorch ignores
5.Grouped batching in SFT
6.Agenctic Sft (Would love to seee it in a lab session)
Hi Guys. Great article. Can you explain this a little more- "Because the training signal abruptly switches from ignored tokens (-100) to active assistant labels, the first few assistant tokens often carry disproportionately high loss. That sudden transition can destabilize training early on. To manage this, many SFT setups use a lower learning rate or a warm-up schedule"