

RAG vs CAG - A deep technical breakdown
A hands-on, technical guide to choosing the right approach



I’ve always seen
not just as a space to share my own ideas and learnings, but as a place where other AI builders could jump in, share theirs, and build something meaningful together.I’ve said it before, but the metaphor still hits home for me: this is meant to be a little oasis, a spot to pause amid the constant flood of hype and surface-level content.
And today’s a big one, friends, we’ve got our very first guest here!
You probably already know who it is: co-founder of
, host of the What’s AI podcast, and co-author of one of the books I’m proud to have on my shelf.Any guesses? 😉

Ladies and gentlemen …
is in the house! 😎Today, he’s here to walk us through the difference between RAG (Retrieval-Augmented Generation) and CAG (Cache-Augmented Generation).
He’ll cover when to use each, how to make them work effectively, and—most importantly—share hands-on examples using the Llama 3.1 8B model.
Take it away, Louis. The mic is yours 🎤
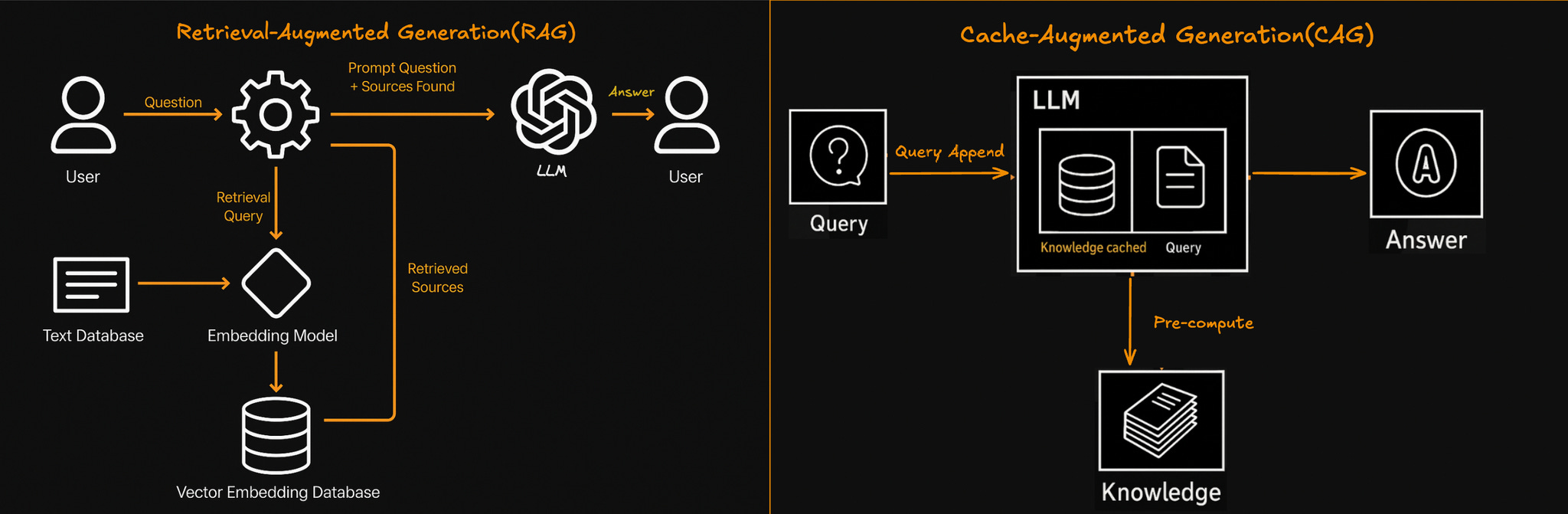
How CAG Works
At its core, CAG, as detailed extensively in the original CAG paper, involves loading your entire document set into an LLM once, precomputing and storing the resulting Key (K) and Value (V) vectors known together as the KV cache. This KV cache can then be efficiently reused across multiple queries without needing to recompute the context each time, significantly cutting down on redundant computations and eliminating retrieval delays.
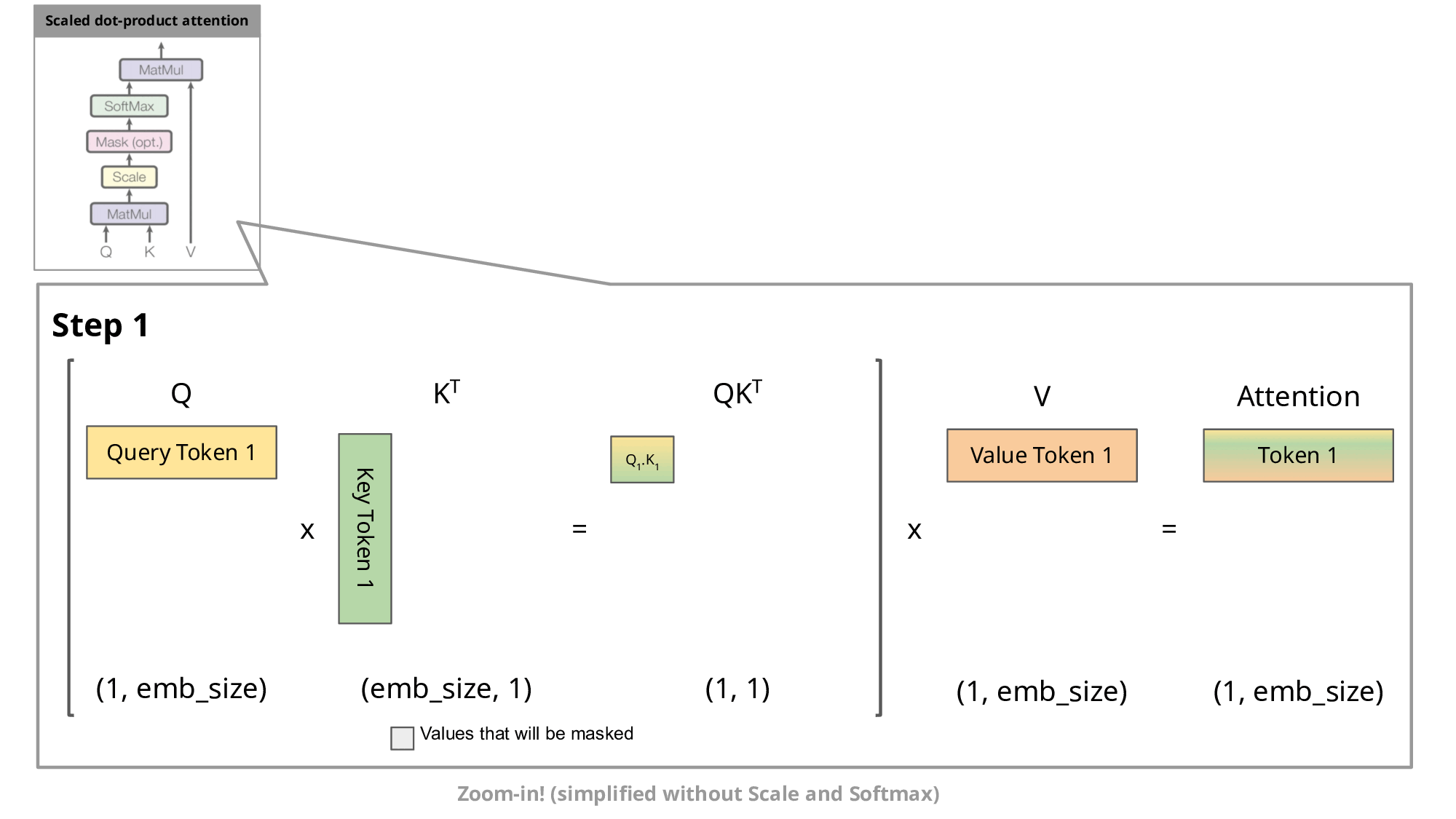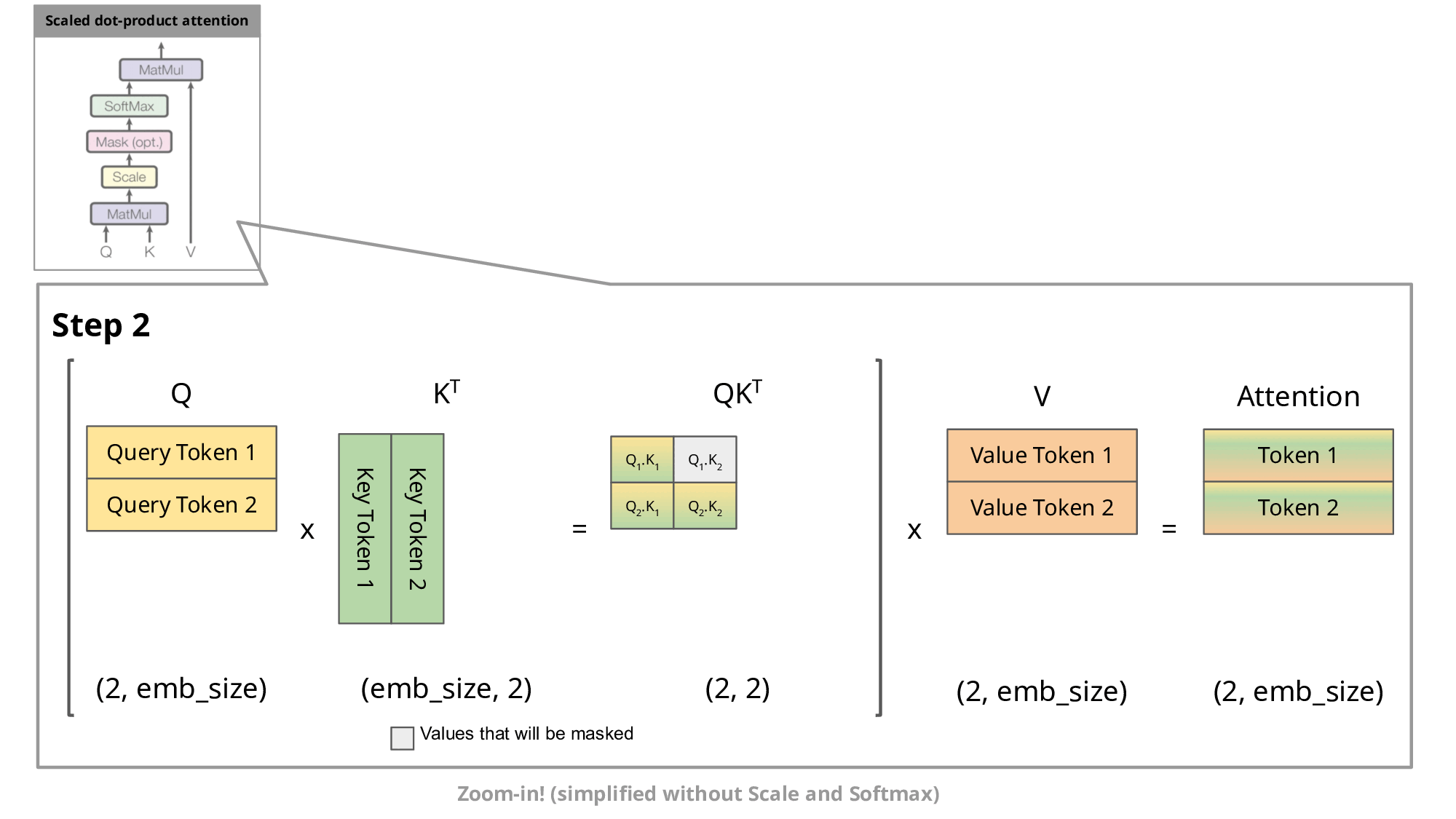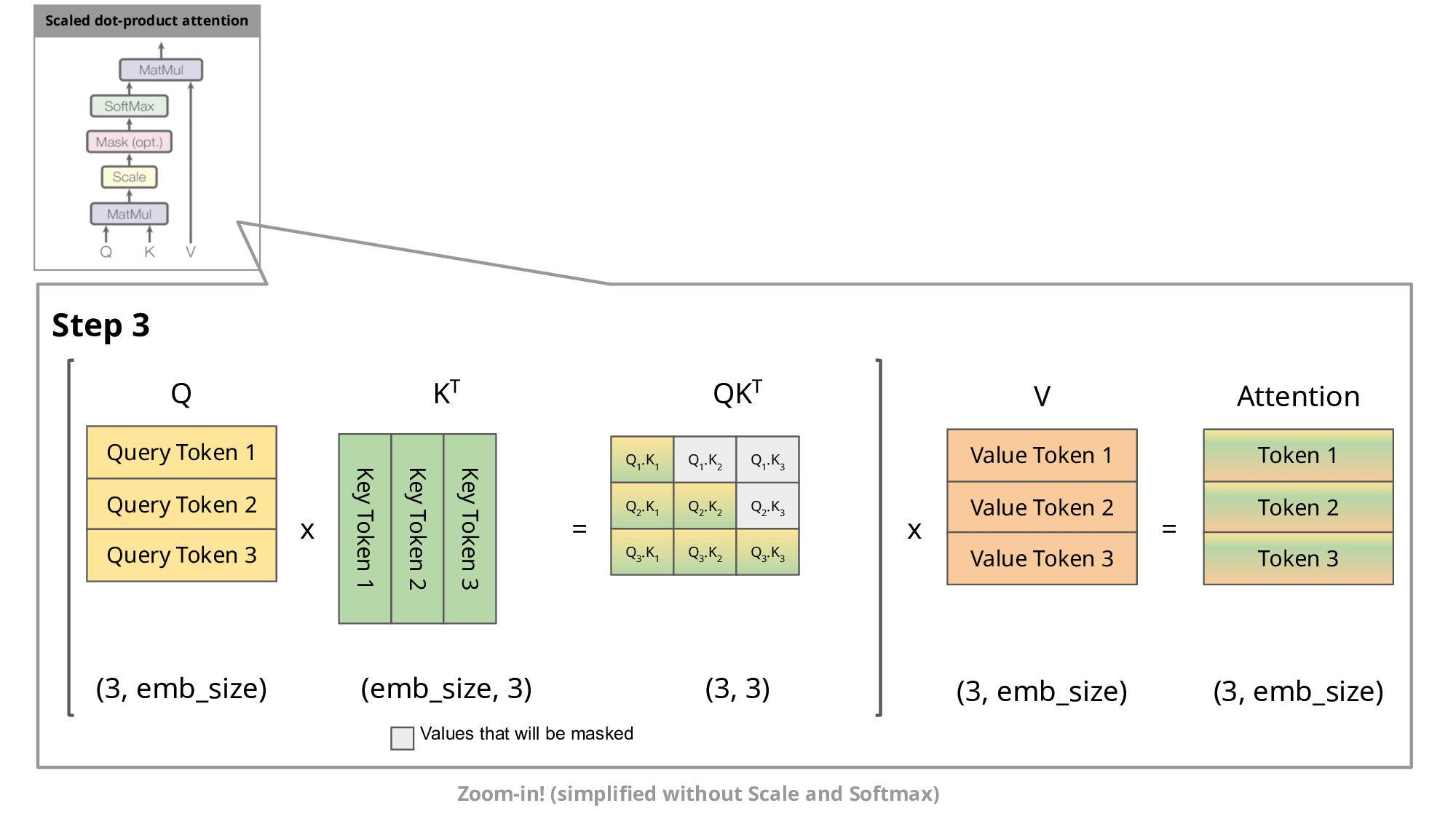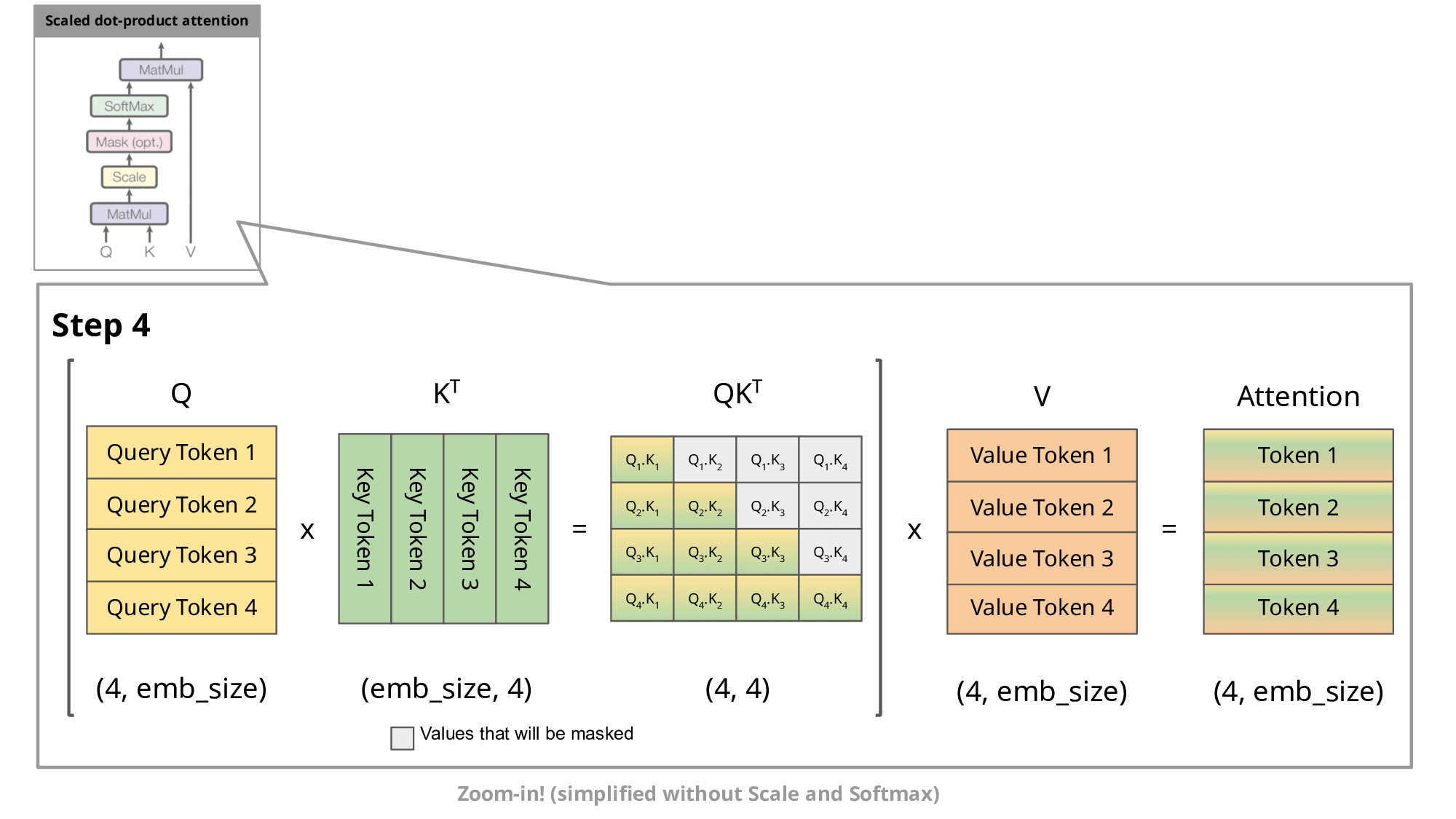
To understand how this works practically, let’s quickly revisit how transformer models process information. Each token in a transformer-based model has three associated vectors:
Query (Q): Asks, "What information am I looking for?"
Key (K): Indicates, "Here is what I can provide."
Value (V): Carries the actual meaning or content.
Take the sentence: "TowardsAI has great courses."
The Q vector for "TowardsAI" is looking for descriptive information.
The K vector of "courses" signals its potential relevance.
The V vector of "courses" provides the actual description: "great courses."
 in the Transformer Architecture and Why Are They Used? | Ebrahim Pichka")
During inference, transformers typically cache these K and V vectors temporarily, discarding them after processing each query. This means every new question requires recomputing these vectors, even if the context remains unchanged.
CAG changes this by keeping the KV cache alive across multiple queries. After preloading your documents once, the model only needs to process the new query tokens during subsequent requests.
As a result, responses become significantly faster and resource-efficient.
Keep in mind, though, that the combined length of cached documents and new queries must stay within the model’s maximum sequence length. Additionally, this method requires direct control over the KV cache, possible with certain open-source frameworks but typically unavailable through commercial APIs.
CAG is most useful when you’re working with a stable and unchanging set of documents in an environment that supports detailed cache manipulation, offering substantial performance gains.
🔔 Hey! Miguel here! Sorry to jump in, Louis.
Just a quick note for anyone who wants to go a bit deeper on what Louis just covered: he’s got a great video that breaks it all down in more detail. Super clear, super useful. Don’t miss it!
CAG vs RAG - A visual comparison
CAG has only become practical in the last few years due to advances in both model architecture and tooling. LLMs can handle extremely long context windows, up to 128k tokens, making it possible to cache and reuse entire documents in memory.
Additionally, frameworks like vLLM and HuggingFace Transformers have also made this easier to implement. For example, vLLM handles prefix caching automatically, and Hugging Face provides explicit access to KV cache management. Coupled with reduced inference costs and improved memory handling techniques, these advancements now allow efficient caching and reuse of static knowledge bases. Previously, this level of caching was too resource-intensive and costly to be practical at scale.
Now that CAG is technically feasible, you might be wondering when it makes sense to choose it over RAG. Let’s break down how these two approaches differ in practice, so you can make an informed decision based on your specific needs.
🏗️ Architecture and Design
RAG retrieves external knowledge at query time using embeddings, vector databases, and reranking, offering flexibility but adding complexity and latency.
CAG simplifies this by preprocessing and caching the key-value (KV) pairs of your entire knowledge base once, enabling faster, more consistent responses, though it requires careful cache management to stay within context limits.
⚡ Performance and Efficiency Characteristics
RAG adds inference latency by computing query embeddings, searching a vector database, and integrating retrieved documents for every request—contributing up to 41% of total latency and increasing token-related costs.
CAG avoids these steps by using a precomputed KV cache, reducing latency and compute, but requires heavy upfront resources and full cache rebuilds for updates, making it less suited for dynamic data.
🔧 System Complexity and Implementation Requirements
RAG is operationally complex, requiring constant tuning, monitoring, and updates across multiple components like embeddings, retrieval, and reranking. This makes scaling and maintaining reliability in production challenging.
CAG eliminates the need for retrieval infrastructure, simplifying maintenance and reducing dependencies by using the precomputed KV cache. However, it introduces challenges in cache design, context limits, and updates, and requires deep expertise in transformer internals and GPU management for large-scale deployment.
💸 Cost and Resource Implications
RAG has high ongoing costs, as each query requires repeated embedding, retrieval, and integration steps. These per-query expenses scale with usage, and additional overhead comes from maintaining vector indices, updating models, and ensuring system reliability.
CAG’s main costs come from the heavy GPU resources needed to deploy and scale large models with long context windows. Running these setups—especially with frameworks like Hugging Face—adds complexity and requires deep expertise in transformers, cache handling, and scalable serving infrastructure.
💡 CAG can offer a lower total cost of ownership for enterprise applications with stable knowledge bases and high query volumes.
However, due to high GPU costs and operational complexity, CAG is only cost-effective when these conditions are met. In dynamic environments or for teams without deep infrastructure expertise, RAG remains the more practical and economical choice.
CAG vs RAG - Hands-On Evaluation
So far, we’ve talked theory. Now let’s see what happens when Cache-Augmented Generation (CAG) and Retrieval-Augmented Generation (RAG) go head-to-head under real-world conditions.
If you’re exploring how to build these systems beyond isolated experiments, especially with open-source tools and real-world constraints, you might find this 60+ hours, hands-on LLM development course a useful next step. It walks through RAG setups in depth, including the tradeoffs that show up only in production.
We implemented both systems using Meta’s Llama 3.1 8B and ran them on the same GPU, with the same knowledge base and question set. Then we compared them on three fronts:
Token efficiency
Output quality
System performance under load
Want to dig into the implementation? Here’s the Colab notebook.
Let’s start with the setup—what’s shared, and where the two systems diverge.
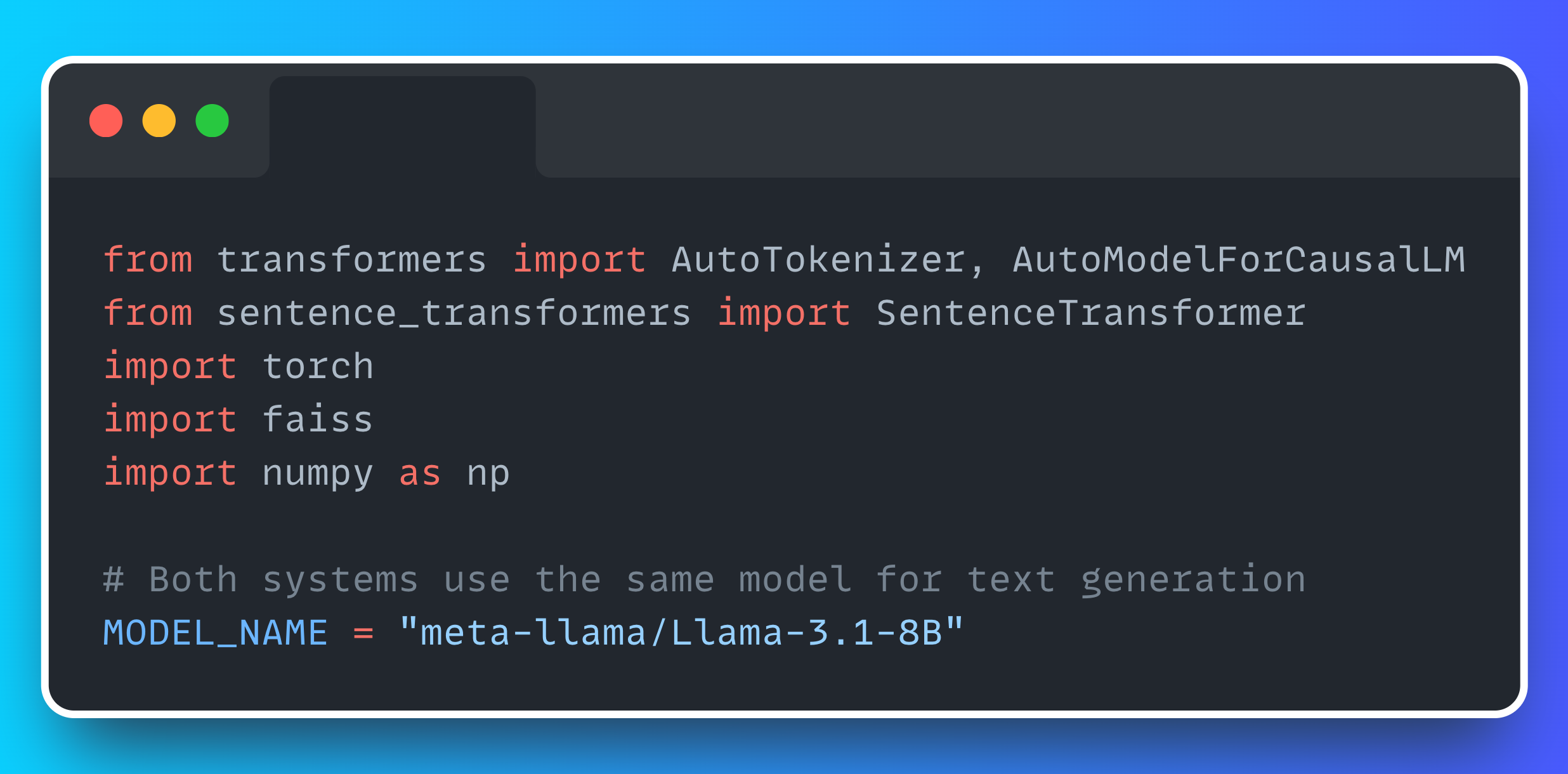
Shared Setup: Loading Llama 3.1
To ensure a fair comparison, both systems use the same model instance: meta-llama/Llama-3.1-8B. This model is efficient enough to run on a single modern GPU while still delivering high-quality outputs.
We used HuggingFace Transformers to handle model loading and generation:
CAG System: Model Loading and Cache Setup
CAG works by feeding the full knowledge base into the model once and saving the resulting attention states into a KV (key-value) cache. From then on, the model only processes new query tokens—everything else is reused.
We need full control over the model’s internals to manage the cache. So we load the model directly:
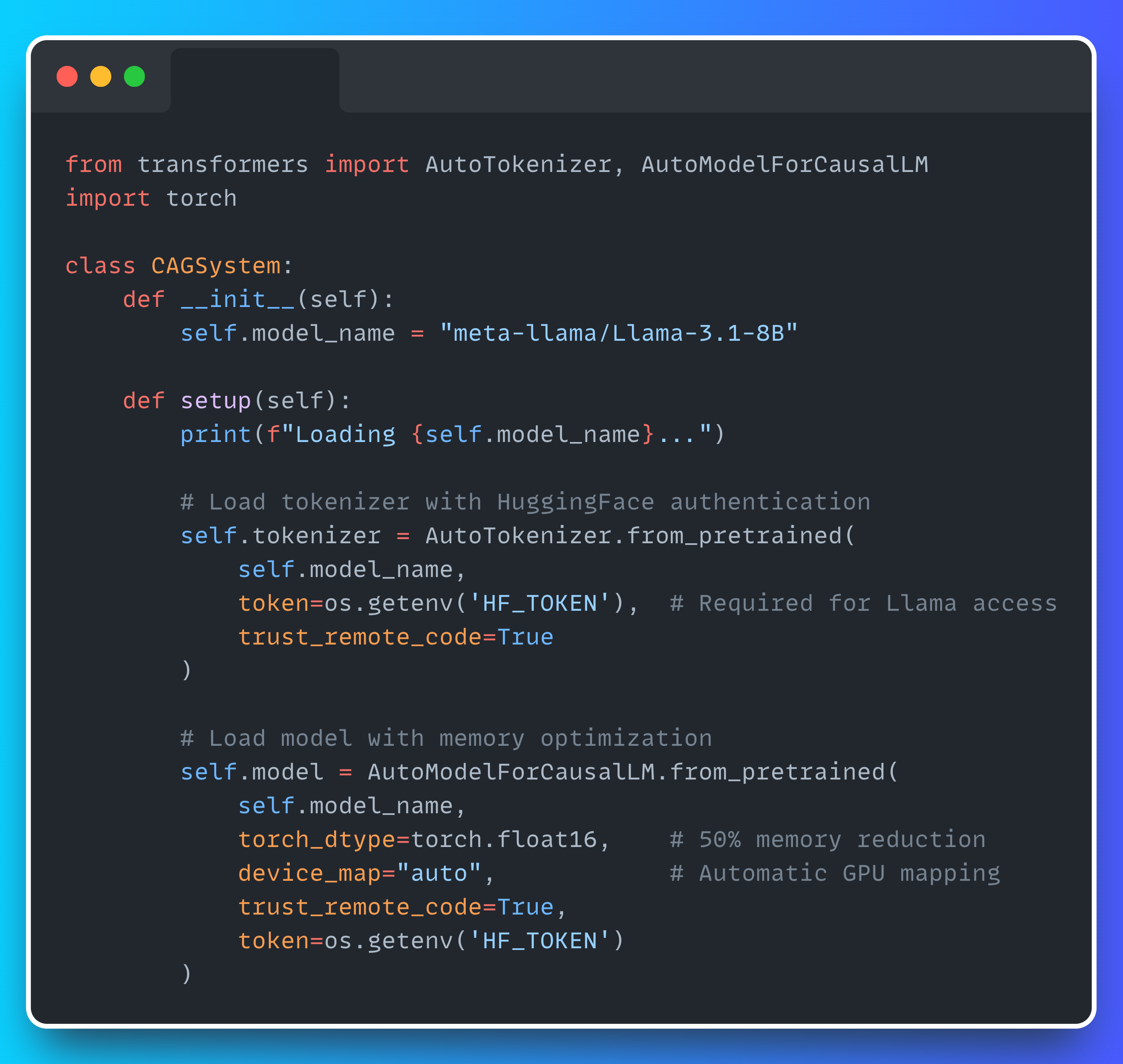
We use 16-bit precision (torch.float16) instead of 32-bit, as it reduces Llama’s memory footprint to ~15GB, letting us run it comfortably on a single GPU. The device_map="auto" setting automatically distributes the model across GPUs if multiple are available, though it's not needed for our setup.
1. Building the CAG Cache
To build the CAG cache, we feed a static document (1,370 tokens) into the model once. This initializes and stores the key-value (KV) pairs for all attention heads across all layers, effectively preloading the model's memory. We use Hugging Face’s DynamicCache to hold these attention states and pass them via past_key_values during generation.
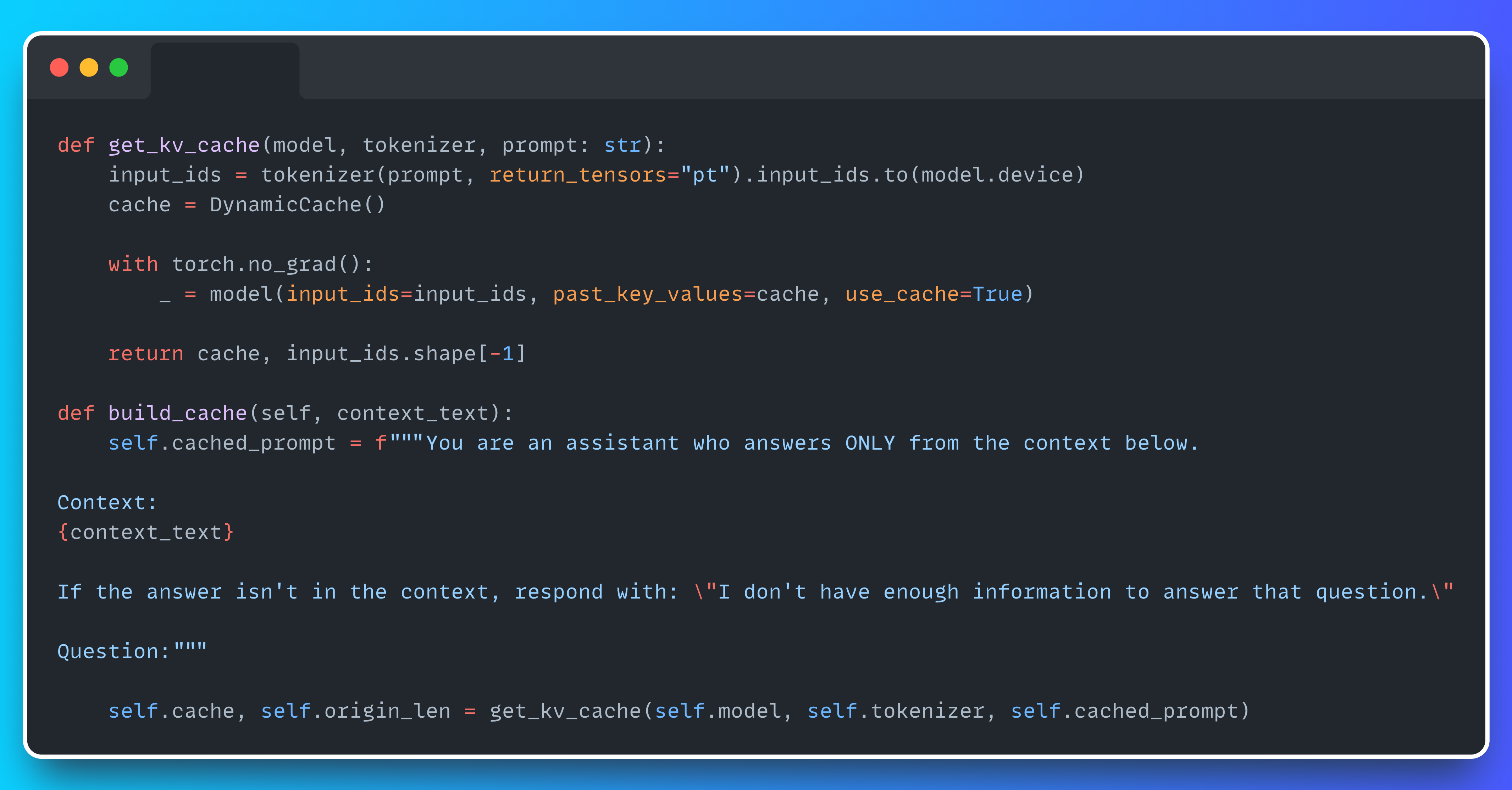
Once this runs, the model is "primed" with your documents and ready to answer questions using only fresh query tokens.
2. Generating Answers with CAG
After the KV cache is constructed, query processing becomes highly efficient since the model reuses the precomputed Key and Value vectors instead of recomputing them for every input.
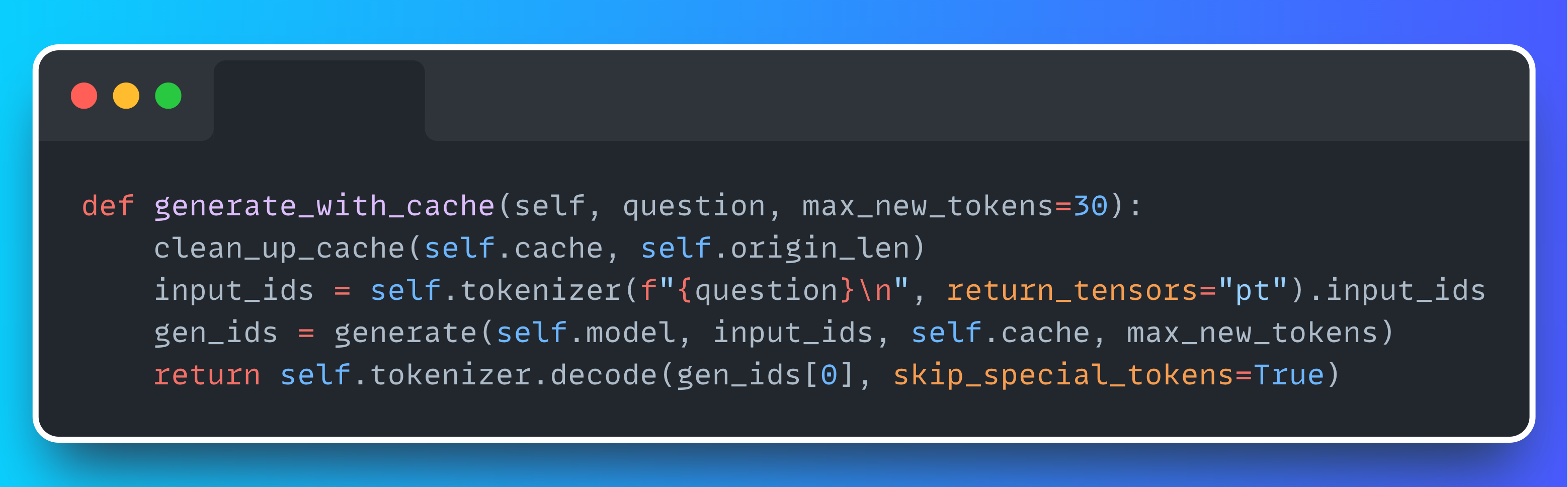
The clean_up_cache function restores the cache to its original state (knowledge base only) before each new query. This ensures that residual keys/values from previous queries don't interfere with the next one:
RAG System: Embedding, Retrieval, and Prompt Assembly
Unlike CAG, RAG doesn’t preload anything. Instead, it fetches relevant documents at runtime for every query. This gives you flexibility, but adds latency and compute overhead.
Let’s break down how it works.
Step 1: Embed the Documents
First, we convert each document into a dense vector (embedding) that captures its semantic meaning. We used a fast, reliable model: all-MiniLM-L6-v2.
Step 2: Build a FAISS Index for Fast Search
Next, we normalize the embeddings and add them to a FAISS index, which lets us retrieve similar documents in milliseconds:
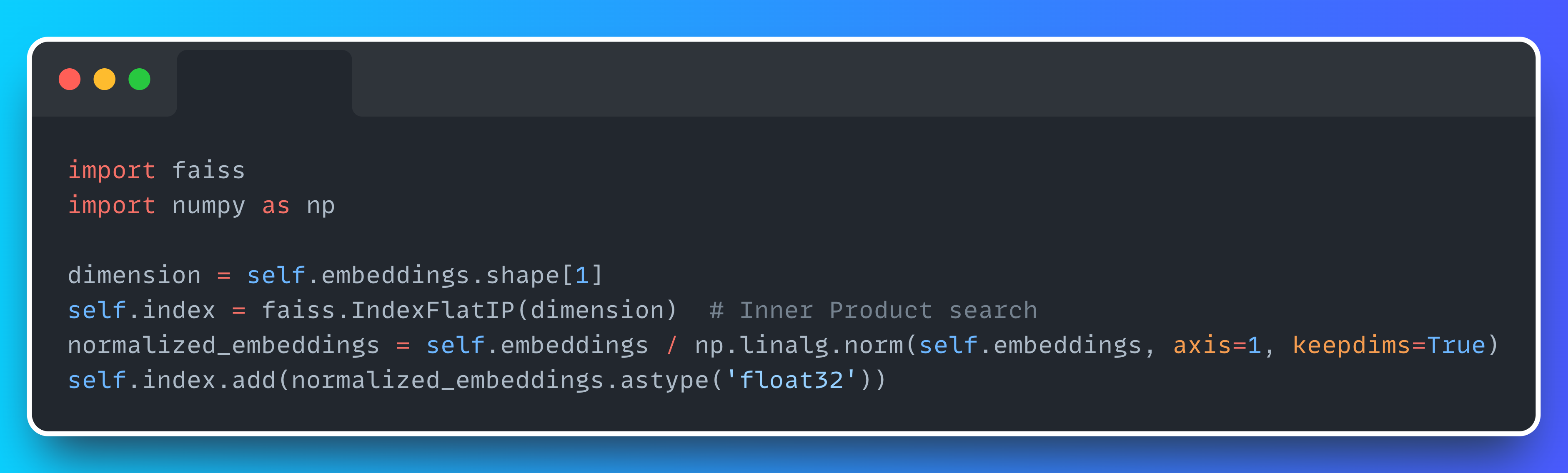
We used IndexFlatIP (inner product) because it’s simple and fast. Combined with normalized vectors, it gives a good approximation of cosine similarity.
Step 3: Process Queries in Four Steps
For each new question, RAG follows the same pattern:
Encode the query
Retrieve top-k matching docs
Construct a prompt with the docs + query
Generate a response from scratch
If you want to check how this 4-step function looks like, got check the
retrieve_and_generatefunction in the colab!
Every query starts from zero: new embedding, new retrieval, full prompt assembly. There’s no memory of past queries or reuse of prior work.
Evaluation Methodology
With both systems running side by side, it was time to ask: how do they perform?
To find out, we ran 7 test questions through each setup—5 in-scope (AI/ML topics) and 2 out-of-scope (general knowledge). To assess token efficiency, we used a custom TokenCounter to track all tokens involved in generation. We also monitored GPU memory usage before and after model loading and during CAG’s cache setup to quantify memory impact and validate reuse across systems.
Let’s see the key findings!
Token Efficiency
Once the CAG cache is built, its advantage is immediately clear.

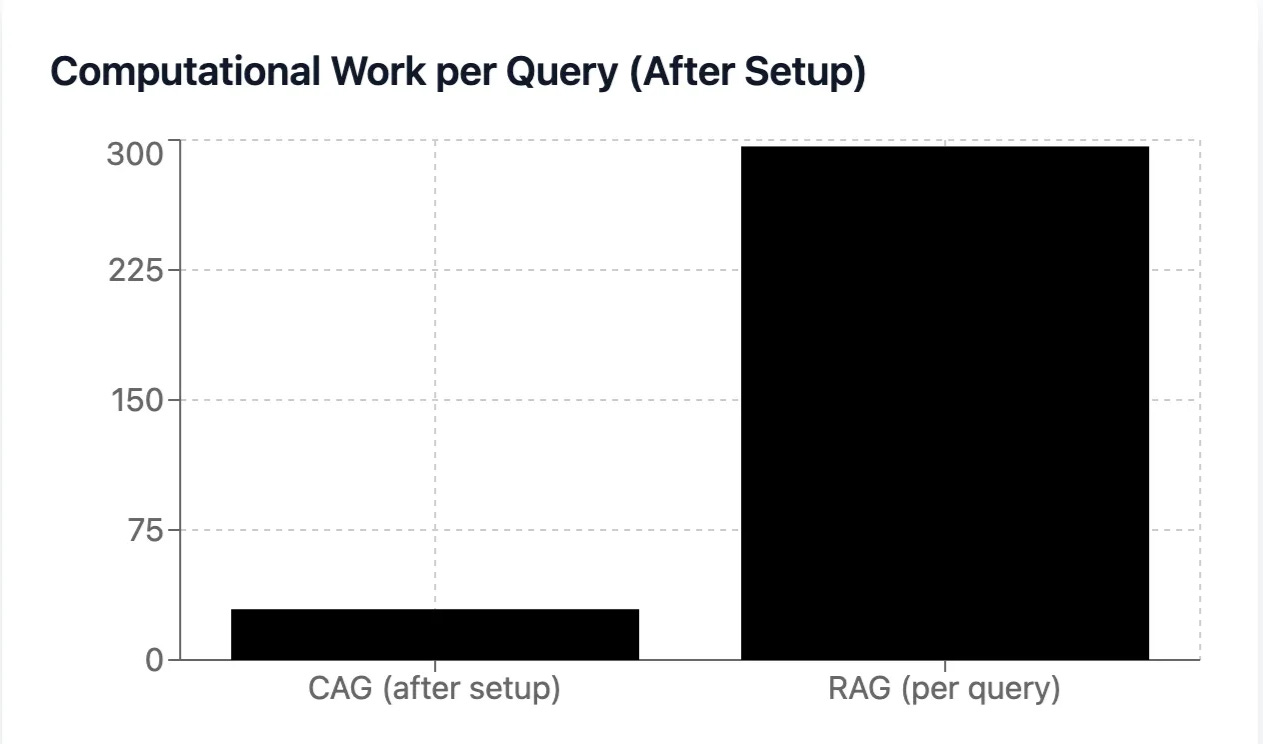
CAG processes ~10× fewer tokens per query than RAG, post-cache.
Break-Even Point: Just 6 Queries
CAG frontloads cost with that one-time cache, but it pays off quickly.
Cache build: 1,370 tokens
Savings per query vs. RAG: ~245 tokens
Break-even point: 6 queries

After 6 queries, CAG becomes more efficient—and the savings compound fast.
Out-of-Scope Behavior
We tested each system with a question not in the knowledge base:
“What is the capital of France?” — a question not present in the context.
CAG: "I don't have enough information to answer that question."
RAG: "Paris"
CAG refused to answer without grounding. RAG retrieved low-relevance documents and let the model fall back on pretraining.
This highlights a key difference:
CAG is constrained by its cache; RAG is not.
Quality Evaluation
We asked GPT-4.1 to score each answer on a 1–5 scale. Here's what we saw:
CAG: Higher average scores (4.46/5.0), perfect out-of-scope handling (5.0/5.0)
RAG: More direct wins (4/7), slightly better in-scope performance
Key finding:
CAG excels at instruction-following, while RAG provides more comprehensive answers
Conclusion
Cache-Augmented Generation isn’t a research novelty or architectural breakthrough. It’s a pragmatic use of what transformer models have long supported: extended context, reusable attention, and deterministic prompts.
What’s changed is viability. With KV cache access now exposed in frameworks like vLLM and HuggingFace—and with context windows stretching to 128K—CAG moves from theory to production.
CAG strips away the complexity of RAG: no embeddings, vector search, or reranking—just a model, static data, and queries. While caches are static, memory-heavy, and not widely supported in APIs, CAG offers a simpler, more consistent, and cost-effective solution when used with stable datasets and high query volumes.
That was simply AMAZING, Louis.
It’s rare to find this kind of depth and clarity out there, and I’m honored you chose to share it here on
.Hoping this is just the first of many future collabs! 🙏
Now, a quick question for you, dear reader:
Would you like to see more guest appearances from other AI builders in the future?
Drop your thoughts in the comments, and as always …
See you next Wednesday! 🫶
 | A guest post by
|
Thanks for having us Miguel! :) Super happy to be the first to guest post and also super happy to jump in and share our insights from Towards AI.
Welcome Louis-Francois on your fabulous waves, Miguel! I skimmed through this fascinating yet dense deep dive. My intention is not to bluntly critique but to help your fans have better clarity/intuition from the onset - why bother?
As it was numerously stated in the post CAG is a different beast, requires thorough understanding of underlying mechanisms (transformer, KV, FSDP, 3D compute etc) for real world setup.
Use cases warranting CAG implementation
——
- You are enterprise, that have expensive GPU capacities and want to strike cost effective latency/throughput balance
- your typical sessions are either very long or across many sessions(users) there is repeated use of context
- context can’t change otherwise (like every caching mechanism) it has to be recomputed
What are we missing?
- evaluate, evaluate, evaluate - perfect prompt and taming hallucinations, alignment requires multilayer/multistage evaluations. Highly dynamic. Forget “black box” CAG. Well, if you insist and do open heart surgery to all kinds of CAG hookups - that’s different pay grade,
not even post-doc might help :-)
- enterprise has to sift through terabytes of data, swap in/swap out for analysis by LLM. Forget about limited context window even with CAG machinery.
RAG with its own demons is here to save you. Or sort of, because more often than not it is clunky and ugly with way too many moving parts and steps (thank you non-determinism and never ending evaluations).
If one is super adventurous and pragmatic (and loaf of determination) front-ending CAG with RAG would be the way to go. Of course, devil is in details. But it is not necessarily CAG vs RAG.