

Building Agent Memory with Knowledge Graphs
Issue #04 — The theory, the trade-offs, and a Graphiti + Neo4j assistant you can run today

Hey friends! 👋
Welcome to Issue #04 of The AI Systems Engineer Journey.
Two issues ago we froze the agentic diagram and walked it component by component. When we got to the memory section, I made a promise and then ran past it.
I said the bug that wakes you at 3am almost always lives in the session memory, but I waved my hands at the fun, contested part of the stack — the long-term memory, the place where the RAG-vs-graph debates actually happen.
🙋 Today we slow down and stand inside that box.
Here's the uncomfortable truth that started this issue for me. Most "memory" in production agents is a vector database with a nice name. You embed everything, you dump it in, you cosine-similarity your way to "relevant" chunks, and you call it memory.
But then a user says "actually, I moved to Madrid last month" and three turns later the agent confidently tells them about the best restaurants in their old city — because the new fact and the old fact both scored high, and nothing in the system knows that one replaced the other.
That's not a memory. That's a filing cabinet with no concept of time, no concept of who or what, and no concept that facts can die.
This issue is about the alternative: representing your agent's memory as a graph — entities, the relationships between them, and crucially, when each of those things was true.
We'll cover the theory (RAG vs graphs, and why graphs are quietly eating certain RAG use cases), a clear-eyed comparison of when to reach for each, and then we'll build the thing: a personal assistant that uses a temporal knowledge graph as its long-term memory — ingesting each conversational turn as an episode, extracting entities and relationships, and resolving them against prior state — backed by Graphiti and Neo4j, running in Docker, where you can watch the graph assemble itself node by node and edge by edge as the agent reasons over it.
Let's go!
Your agent has amnesia
Let me describe a system you've probably built (I have, more than once).
You wire up a chat agent. You give it a vector store for "memory." Every user turn gets embedded and stored; every new question retrieves the top-k most similar chunks and stuffs them into the prompt. Clean, fast, ships in an afternoon.
Then it meets reality:
The user mentions their partner Marta in week one and their colleague Marta in week three. The store now has two blobs that both say "Marta," and retrieval cheerfully mixes them. The agent can't tell two people apart.
The user got promoted. The old title and the new title are both sitting in the store, both semantically about "the user's job," both retrievable. The agent can't tell which fact is current.
The user asks "who introduced me to my running club?" — a question that requires hopping across three separate facts (you know Carlos → Carlos runs with the club → the club is where you met Sofía). Vector similarity retrieves each fact in isolation. The agent can't connect them.
This is the failure mode I think of as digital amnesia married to déjà vu (I know, I'm inspired today 🤣).
Forgetting what matters while surfacing what doesn't. And it's not a tuning problem. You can swap embedding models, crank up top_k, add a reranker, and you will not fix it, because the representation itself has no slot for identity, relationship, or time.
Human memory doesn't work like a pile of documents. It's a web — people, places, things, and the connections between them, layered with a sense of when. When your partner changes jobs, you don't keep both jobs as equally true. You update. The old fact becomes history, not noise.
That's what a knowledge graph gives an agent. And that's the whole issue.
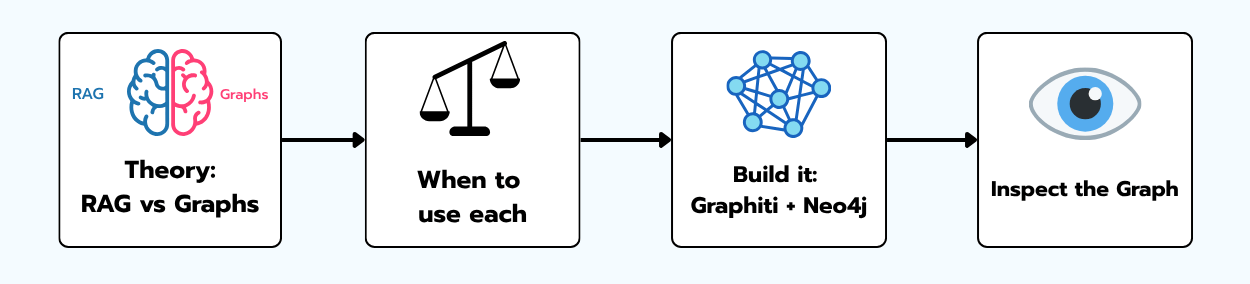
RAG and Graphs
Retrieval-Augmented Generation is, mechanically, a five-step pipeline, and it's worth saying it plainly because half the confusion in this space comes from people meaning different things by "RAG."
You chunk your documents into pieces (a few hundred to a thousand tokens each). You embed each chunk into a vector. You store those vectors in a vector database. At query time you embed the question and retrieve the chunks whose vectors are nearest. You hand those chunks to the model as context, and it generates an answer grounded in them.
It is a genuinely great pattern. For a static body of documents — product docs, a knowledge base, a pile of PDFs — RAG is hard to beat.
Modern implementations get even better by going hybrid: combining classic keyword search (BM25, which nails exact matches) with vector search (which nails semantic intent), then fusing the two ranked lists with something like Reciprocal Rank Fusion.
That hybrid approach handles both "red dress with pockets" (lexical) and "red dress for a dinner date" (semantic) in one query. It's mature, it's cheap, it scales, and the ecosystem is enormous.
So this is NOT a "RAG is dead" issue. RAG is excellent at the thing it was built for: finding the most relevant passage in a large, mostly-static corpus.
🙋 The trouble starts when we ask it to be a memory.
What a knowledge graph actually is
A knowledge graph stores information not as text chunks but as a network. The atomic unit is the triple: a subject, a relationship, and an object.
(Luis, WORKS_WITH, Miguel)
(Luis, TEACHES, "Grokking Agents")
(Miguel, LIVES_IN, Vigo)
Each "thing" (Luis, Miguel, Vigo) is a node. Each connection is a labelled, directional edge. The meaning lives in the structure, not in a fuzzy distance score. And that buys you four things vector stores fundamentally can't give you:
Explainable reasoning. The path from question to answer is a literal path through the graph you can read out loud. "Why did you recommend that? Because you're connected to Carlos, who is connected to the running club, where you met Sofía." No hand-waving about embeddings.
Multi-hop reasoning. Questions that require chaining several facts together become graph traversals instead of praying that all the needed chunks happen to land in the top-k.
Entity resolution. Two mentions of "Marta" can be reconciled into one node — or kept as two distinct nodes — explicitly. The graph has a concept of identity; the vector store only has a concept of similarity.
A flexible schema. New entity types and relationship types can be added without a migration. The graph grows organically as the world the agent knows about grows.
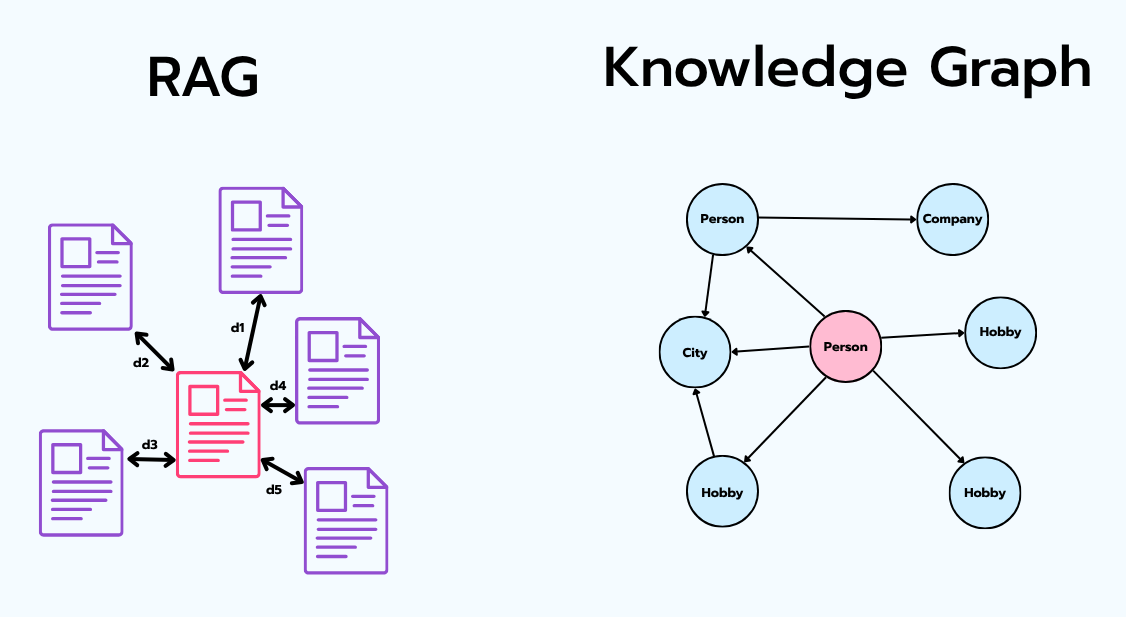
The dimension that changes everything: time
Here's the piece most introductions skip, and it's the most important one for agent memory specifically.
A plain knowledge graph is still a snapshot. It tells you what's true now, but the real world is a movie, not a photo.
People get promoted. Companies get acquired. The user moves from Barcelona to Madrid. A regular graph, asked to absorb the new fact, faces the same dilemma as the vector store: keep both and contradict yourself, or overwrite and lose history.
A temporal knowledge graph solves this by attaching time to the relationships themselves. Every edge carries validity information — roughly, when did this become true and when did it stop being true. The fact "the user lives in Barcelona" isn't deleted when they move; it's marked as no longer valid as of the move date, and a new "lives in Madrid" edge is created. Both are preserved.
The graph can now answer "where did the user live last spring?" and "where do they live now?" with equal confidence — and it never contradicts itself, because every fact knows its own lifespan.
This is the leap. It's the difference between a memory that accumulates and a memory that evolves.
How graphs are quietly replacing RAG (in some places)
For a while, the dominant "graph + LLM" pattern was Microsoft's GraphRAG-style approach: extract entities and relationships from a big static corpus, cluster them into thematic "communities," and have an LLM pre-compute summaries of each community so queries can be answered against those summaries. It produces wonderfully rich, context-aware answers over large static datasets.

But that approach was built for static data. When the underlying information changes, you're looking at recomputing large parts of the graph, and the multi-step summarisation at query time can take tens of seconds.
That's fine for "analyse this fixed report." It's a non-starter for an agent that needs to update its understanding of the world as the conversation happens and respond in real time.
This is exactly the gap that frameworks like Graphiti (from Zep) were built to close — and it's where graphs are genuinely displacing naive RAG for agent memory:
Graphiti ingests new information as discrete episodes (a message, a document, an event) and incrementally folds each one into the graph — extracting entities and relationships and reconciling them against what's already there, without recomputing the whole graph.
It uses a bi-temporal model: it tracks both when an event actually happened and when the system learned about it. When new knowledge contradicts old knowledge, it doesn't throw the old fact away — it uses the timestamps to mark it as superseded, preserving history.
Retrieval is fast because it avoids LLM calls at query time. Instead it combines vector (semantic) search, BM25 (keyword) search, and graph traversal into one hybrid query — Zep reports retrieval latencies low enough (sub-second at the 95th percentile) to sit comfortably behind a voice assistant.
Notice what that hybrid retrieval is doing: it keeps everything good about RAG (semantic + keyword search) and adds the graph structure and temporal reasoning on top. Graphs aren't replacing the retrieval techniques RAG taught us. They're wrapping them in something that finally understands identity and time.
💡 The one-line version: RAG finds the most similar text. A temporal knowledge graph remembers the most relevant, current, connected facts — and can show its work. For long-lived agents, that's not a nice-to-have; it's the difference between a tool and a companion.
When to use each
If you take one practical thing from this issue, take this section. Choosing between RAG and a graph isn't about which is better — it's about matching the architecture to what your application actually needs to remember and reason about.
Reach for vector RAG when…
You're doing document search or Q&A over a large, mostly-static corpus — docs, manuals, a knowledge base, an FAQ bot.
Relationships and time don't matter to your queries; you just need the most relevant passage.
You want the simplest, cheapest, most battle-tested option, with predictable scaling costs.
You need very high write throughput — embedding a chunk is far cheaper than running an LLM extraction over every episode.
Reach for a temporal graph (e.g. Graphiti) when…
You're building an agent with persistent, long-term memory across sessions — a personal assistant, a customer-support agent that remembers a customer's history, an enterprise system that tracks how knowledge evolves.
Who-relates-to-whom and how-things-change-over-time are first-class questions for you.
You need entity tracking and disambiguation (two people named "Marta") and multi-hop reasoning ("why did X happen?").
You want answers your system can explain by pointing at the path it took.
And, often, use both
This isn't a religious war!
A mature system frequently runs RAG for the big static document piles (the company handbook, the product docs) and a graph for the dynamic, relationship-rich memory (who the user is, what they care about, how that's changed), then merges results. If you're migrating, the gentle path is: keep RAG for historical / static content, route new relationship-heavy data into the graph, and let them coexist.
⚠️ A fair warning before we build. Graphs aren't free. Every episode you ingest costs an LLM call (entity + relationship extraction), which means real latency (roughly half a second to a couple of seconds per episode) and real money at volume. The extraction is also not guaranteed complete — the LLM might miss an implicit relationship, and there’s no schema to validate against. If your use case is "search 10 million static documents as fast and cheap as possible," a graph is the wrong tool. Know what you're buying.
Let's build it
Enough theory. Let's build the thing and watch the graph form.
We're going to build a personal assistant with graph memory. You talk to it like a normal chat assistant. Behind the scenes, every exchange becomes an episode that Graphiti folds into a Neo4j knowledge graph — extracting the people in your life, the places, the preferences, the relationships — and then every new question is answered using a hybrid search over that graph.
Over a few conversations, it builds a genuine model of you: who you know, where you live, what you're into, and how all of that connects.
And because it's all in Neo4j, you can open Neo4j Browser and literally see the nodes and edges appear as you chat. That’s the magic moment for this issue.
📌 A note on frameworks. I'm deliberately keeping the core example framework-free — just
graphiti-core, Neo4j, and a thin chat loop — so you can see exactly what's happening with nothing hidden behind an abstraction.
The architecture
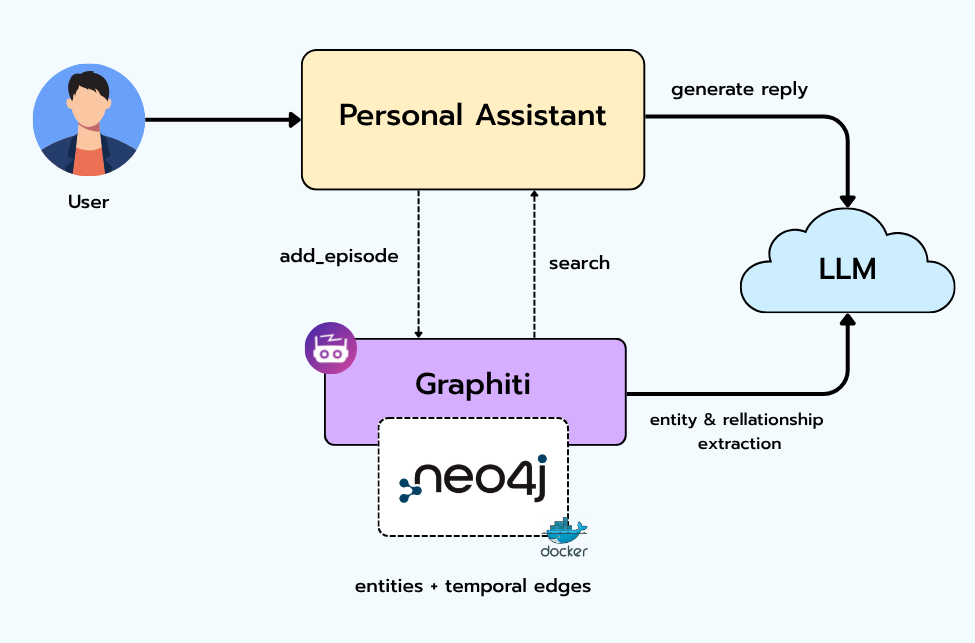
The flow, in words:
The user sends a message.
The assistant first searches the graph for anything relevant it already knows about the user (their name, the people and places they’ve mentioned, current facts).
It feeds that retrieved context to the LLM and generates a reply.
It then stores the exchange as a new episode — Graphiti extracts the entities and relationships, reconciles them with what's already in the graph, time-stamps the edges, and updates Neo4j.
Repeat. The graph gets richer every turn.
Each user gets their own group_id namespace, so one assistant can serve many people without their memories bleeding into each other.
What you'll need
Docker + Docker Compose (for Neo4j — no manual database install).
Python 3.10+.
An OpenAI API key (Graphiti defaults to OpenAI for both the extraction LLM and embeddings; you can swap providers, but we’ll keep it simple).
Everything below is in the downloadable zip at the end of the issue. I’ll walk the important pieces here.
Get the code
The full project — Docker Compose, the Graphiti memory layer, the assistant loop, a scripted seed demo, and the optional ADK stub — is packaged in the zip below. Grab it and follow along; everything in this section maps directly to a file in there.
